Cette page désormais concentre les ressources de nos ateliers r. Ce sont des carnets de recherche en Markdown qui réunissent sur une seule page html, les données, le code, les résultats et leurs analyses … et permettent de satisfaire aux nouvelles exigences de la “reproducibility” .
En voici les premiers qui nourrissent les cours que j’anime cette année à Nanterre et ailleurs, ils sont localisés sur le sous-domaine r.benavent.fr, comme de simples pages html. On y rattache bien surtex2.r, le blog de nos explorations textuelles.
Pour participer aux ateliers, il est demander aux étudiants d’installer r, puis RStudio qui est l’environnement de travail. Ils sont encouragés à installer les packages requis à l’avance avec Rstudio (voici un tutorial). Rcmdr est sans doute le premier package à installer, il permet de disposer d’une interface graphique analogue à celle de spss et facilite la prise en main de r. On utilisera largement le markdown avec son augmentation bookdown.
Carnets de notes
les carnets de notes se retrouvent sur cette page, mais surtout on développera plutôt sur le compte github.
Les voyages sont faits pour être vécus mais ce qui en reste ce sont des mots. Des livres de voyageurs, le journal de bord des marins, et aujourd’hui le commentaire des expériences de consommation. A l’heure du post-exotisme ( pas celui-ci), quand le touriste pense rencontrer une culture authentique mais bien souvent façonnée par son propre regard, ce qui compte est moins ce que l’on a vécu que ce que l’on en garde : des selfies et le commentaire des lieux de séjours. C’est certainement moins poétique que Cooket Gauguin, mais plus profitable pour l’industrie du tourisme.
Et c’est à l’occasion d’un de ces voyages, avec l’aide des collègues du Cetop, des étudiants du master de marketing de l’UPF, et l’écoute du team de Tahiti tourisme, que nous nous sommes lancés dans l’analyse des sentiments exprimés par les touristes à propos de leur séjour avec une petite incursion dans les packages de text mining de r. Il n’y avait pas de meilleure place pour apprécier la critiques des auberges du paradis.
Pour la méthode, il s’agit d’abord de scrapper, avec les ressources du package rvest, le site de TripAdvisor. La Polynésie est isolée, trouvant ses clients dans trois grands bassins à plus de 10h de vol : l’Asie , les EU et la France. Il y a environ 150 hôtels et 300 pensions. Les résultats donnés dans cette note, sont établis sur la base d’une première extraction centrée sur Tahiti et portant sur 7700 commentaires. On généralisera plus tard sur les 77000 commentaires sur l’ensemble des archipels.
Ce corpus fait l’objet de deux types d’analyses comme on commence à le faire systématiquement dans ce type d’exercice : mesurer la tonalité positive ou négative (le sentiment) et les sujets évoqués ( topic analysis). Pour la première, on emploie tidytext, pour la seconde le modèle LDA du package Topicmodels.
Voici la présentation de travail (demo), avec quelques éléments de code, rendez-vous au piurn 2018 pour une présentation plus complète.
L’objectif du cours est de donner une culture quantitative élargie aux étudiants, leur laissant le soin d’approfondir les méthodes qui pourraient être utilisées dans le cadre de leurs projets de recherche.
Il est aussi de le donner le sens critique nécessaire pour évaluer les protocoles employés dans la littérature courante de gestion. Il est dispensé aux étudiants du Master Management de l’Innovation parcours MOPP et GDO.
L’environnement est le langage r avec le package Rcmdr et rstudio qui sont à installer au préalable. On trouvera un manuel d’initiation ici et pour la culture générale on encourage à suivre r-blogger.
On travaillera d’abord sur un cas issu du mémoire de Master Marketing de Pauline Vautrot qui a fait l’objet d’une publication. Il porte sur l’effet des preuves de transparence sur l’évaluation d’un moteur de recommandation. Les éléments se trouve sur le dossier google drive.
On utilisera surtout un échantillon de données (n=~35000) de la base European Social Survey ( vague 8) en particulier les questions relative au bien-être, à la confiance, et aux valeurs ( Schwartz) . Les éléments de travail se trouvent ici. Les résultats sont publiés sur cette page, d’autres éléments sur la confiance en France sont aussi disponibles et illustre ce qui est possible de faire avec ces outils.
C’est l’occasion d’introduire, ou de rappeler, les méthodes statistiques suivantes :
Analyse univariée avec r
Analyse bivariée : Test du khi², analyse de variance, corrélations, …
On explorera les principes d’analyses textuelles avec le cas des hôtels de Tahiti et le blog tex2r
Evaluation : au choix : une étude statistique menée avec r, ou l’exposé synthétique d’une méthode (en 4 pages). C’est un travail individuel. A rendre pour le 30 Janvier 2019.
Quelques idées de sujet :
Analyse conjointe et modèle de choix ()
Modèle de croissance ( SEM)
Méthode de la différence des différences (causalité)
Modèle de régression avec variable instrumentale ( causalité)
Modèles VAR ( économétrie, causalité) : avec une belle application pour l’analyse des effets croisés des médias sur les ventes.
Modèle linéaire hiérarchique et analyse multi-niveaux ( économétrie)
Mesure des attitudes implicites (Échelle), en se concentrant sur les travaux du Project Implicit
Machine learning et catégorisation de document en explorant les solutions proposées par MonkeyLearn pour la catégorisation.
Analyse des rendements anormaux (finance) ou event Analysis. Une application à l’effet des surprises ( positives ou négatives) est un très bon point de départ.
Régression avec auto-corrélation spatiale ( économétrie). Pour une introduction cette application en marketing en donne une très bonne idée.
Modélisation multi-agent appliquée au sciences sociales en passant par l’étude des modèles standard de Netlogo.
Analyse des réseaux sociaux ( Réseaux)
Data visualisation : de la grammaire des graphes à l’inventaire des solutions créatives en passant par l’ergonomie ou la psychologie.
Tests d’équivalence structurelle et comparaison inter-culturelle
….
Des lectures en voici un florilège.
Les séances ont lieu les mardi de 18h00 à 20h30 à l’Ecole des Mines de Paris (Luxembourg) - Pour poursuivre voir aussi l’Atelier Doctoral.
L’objectif de l’atelier, organisé dans le cadre des enseignement de l’ED EOS, est la prise en main de r au travers de l’interface graphique Rcmdr de Rstudio et du markdown.
Il s’agit aussi de découvrir la communauté r et ses ressources en 4 séances de 3 heures : décrire, expliquer, modéliser.
Public visé et pré requis : Doctorants et autres chercheurs. Connaissance des tests statistiques et autres statistiques élémentaires. Une habitude de SAS ou SPSS fera du bien.
Les participants doivent installer Rstudio au préalable. l’interface pour démarrer est Rcmdr, c’est le premier package à installer au préalable.
Calendrier de la formation (période de l’année): 19 et 20 décembre 2018 et 21 janvier 2019 (9h30-12h30 : 13h30-16h30) - Lieu : Université Paris Nanterre Bat A 3ème étage salle 304 ou 305)
Inscription : envoyer un CV à [email protected] avant le 10 décembre. - nombre maxi d’inscrits : 15.
Programme
Le jeu de donnée utilisé provient de l’European Social Survey. On s’intéressera en particulier à l’évolution de la confiance en France de 2002 à 2016 : on trouvera ici les données et le fichier markdown. Les résultats peuvent être consultable sur cette page. On regardera en complément ce document ( Bonheur et valeur dans 18 pays européens)
1 : l’environnement r: communauté, packages, langage et prise en main avec Rcmdr. Comparaison de moyennes, corrélation, représentation graphique avec ggplot(pour des exemples voir ici ou là )
2 : Clustering ( package Ape, dendro…) et analyses multidimensionnelles ( AF, AFC, MDS)
3 : Régression avec r: des MCOs au modèle linéaire généralisé (Logit, Poisson, etc) (package lme4, Stargazer pour des présentations standardisées.
4 : Échelles de mesure et équations structurelles avec Psych et Lavaan : on traitera notamment de l’influence de la confiance sur le bien être.
Une session supplémentaire le 21 janvier sera consacrée au text mining
5 : Analyse lexicale avec tm , Rtsne et LDA , vec2word, sentiment analysis et quanteda. Le cas de l’analyse de topics d’un flux de tweets. On s’appuiera sur le blog tex2r.
ECTS : la participation au séminaire donne droit à 3 crédits.
Ressources :
r blogger : un meta blog centré sur r , très riche en exemple et application.
StackOverflow : plateforme de Q&A pour les développeurs, r y est fréquemment mis en question
PS : un cours similaire est donné dans le cadre du Master Management de l’innovation GDO/MOPP.
La doc de ggplot2, le package des graphiques élégants.
Crédit Photo : comme souvent l’excellent Jeff Safi
Il y a des moments de bonheur. Par exemple, celui où on découvre un jeu de données merveilleux et que l’on part à son exploration. Ce jeu de donnée est celui de l’ESS Eric. Parfaitement préparé et documenté, il cumule 8 vagues d’enquêtes menées tout les deux ans, dans plus d’une vingtaine de pays, et porte chaque fois sur près de 2000 personnes, au total près de 300 000 répondants. Un véritable baromètre du bonheur, du bien être, des valeurs, de la confiance, de l’engagement politique et civique, des sentiments de discrimination, des orientations politiques et religieuses, de l’inclusion.
Une mine d’or. Je ne serais pas le premier à m’y plonger, des centaines de publications ont déjà employé telle ou telle fraction des données. C’est aussi un très bel outil pédagogique, une base magnifique pour introduire à la puissance et l’élégance de r et du traitement statistiques des données, d’autant qu’elles sont aisément téléchargeables, sous des formats remarquables de limpidité.
Pour le spécialiste de marketing qui a été nourri au lait de la relation client, et par conséquent de celui de la confiance, il y a l’occasion remarquable de revenir, à grande échelle (la base que nous exploitons représentent 220 000 individus au cours de 6 vagues et dans 16 pays) sur le lien qu’elle entretient avec la satisfaction, et d’en tester la solidité à travers les pays, le temps, et les strates sociales. On se concentrera dans cette analyse sur un tout petit nombre de questions relatives à trois variables clés.
le bonheur bien sûr, mesuré comme satisfaction dans la vie, et sentiment de bonheur actuelle ( 2 items). L’état de santé perçue est aussi mesuré, mais nous ne le prendrons pas en compte, pas plus que la satisfaction à l’égard de l’économie qui dans des premiers tests se révèle peu lié au bonheur. C’est notre variable dépendante.
la confiance interpersonnelle : se méfie-t-on des autres, espère-t-on leur aide, sont juste juste ? 3 items sont proposés qui présente un alpha de l’ordre de 0,80.
la confiance dans les institutions dont une analyse plus fine révèle qu’elle possède trois facettes : l’administration, le politique, les institutions internationales. Nous les traiterons comme une dimension. l’alpha est de 0.92.
Notre modèle est donc extrêmement simple, une regression à deux variables corrélées. on l’estime avec un modèle SEM évalué avec l’élégance du Package Lavaan. Le temps de calcul ne dépasse pas la seconde, un poil plus quand des modèles à nombreux groupes sont estimés.
Le résultat du modèle est résumé dans le graphe suivant, il montre que le bonheur dépend plus de la confiance interpersonnelle, locale, de voisinage, de l’idée qu’on se fait de l’humain que de la confiance dans les institutions. Clairement deux fois plus. Si une unité de confiance interpersonnelle supplémentaire est obtenue, c’est 0,36 de bonheur gagné, le même gain de confiance envers les institutions s’accroît le bonheur que de 0,16 unités. La confiance reste un sentiment général, une corrélation de 0, 55 est enregistrée entre ses deux facettes, elles évoluent de manière conjointe ce qui se comprend : de bonnes institutions conduisent à ce que les gens se fassent confiance,, mais pour faire confiance aux institutions il faut aussi faire confiance aux gens qui les habitent.
Avoir autant de données pour une presque trivialité peut sembler inutile, sauf si l’on cherche à voir ce qui peut faire varier ce modèle. L’idée est donc simplement d’évaluer ce modèle pour différents groupes. La seule chose à faire est de modifier l’ajustement avec cette ligne :
Le même modèle est estimé pour les différents groupes (le pays dans l’exemple) avec la contrainte que les loadings sont égaux entre les groupes : on mesure les mêmes variables partout ( avec group.equal). Ce qui peut changer c’est le poids des variables de confiance sur le bonheur, et leur degré de corrélation. Cette approche consiste en fait à faire une sorte de méta-analyse. Répéter l’estimation du modèle sur différent groupes et analyser la variance de ses paramètres.
Avant de présenter les résultats, un élément préalable doit être communiqué : le niveau de bonheur au niveau du pays est inversement lié à la variance du bonheur au sein du pays. Autrement dit ce qui fait baisser l’indice de bonheur c’est l’inégalité du bonheur! Ce qui fait un pays heureux c’est quand tous le sont également, c’est le cas dans les pays du nord de l’Europe, le sud et l’est sont soumis aux inégalités.
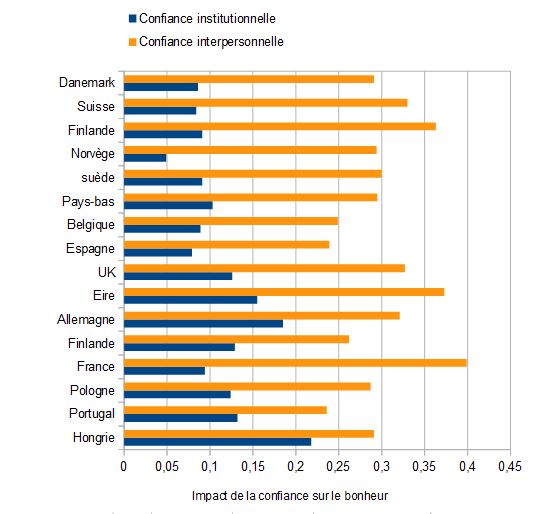
Dans le diagramme suivant, le poids des paramètres du modèle pour chaque pays est indiqué par la longueur des barres horizontale. On retrouve le pattern général, la confiance interpersonnelle tourne autour de 0.35, et c’est en France qu’elle est la plus déterminante. La confiance dans les institutions pèse le plus sur le bonheur en hongrie. Les pays sont classés par ordre de bonheur, s’il y a des différences il est difficile de comprendre pourquoi.
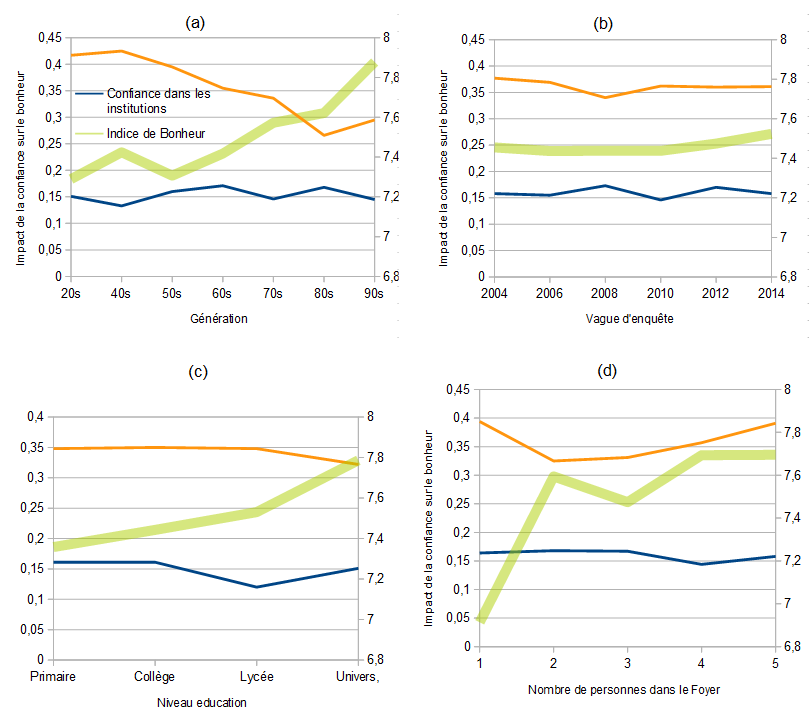
Tant qu’à faire nous avons systématisé cette approche sur un certains nombre de variables. Tous les résultats sont regroupés dans le graphique suivant. Et en voici les enseignements principaux.
Premier point, dans la figure (b) on n’observe pas de changement notable dans l’indice de bonheur sur une période de 10 ans. Le poids des deux facettes de la confiance sur le bonheur reste stable aussi. C’est sans doute le fruit de l’homéostasie du bonheur et de la satisfaction. Le monde peut changer, il se réajuste.
Second point, dans la figure (a) on observe un changement important d’une génération à l’autre : l’influence de la confiance interpersonnelle sur le bonheur est plus faible pour les plus jeunes, qui sont aussi les plus heureux. Auraient-ils moins besoin des autres, des proches pour jouir de la vie? le poids de la confiance institutionnelle lui ne varie pas et reste identique à travers les génération. Ce résultat est d’autant plus intriguant, qu’il ne se retrouve pas dans le niveau de diplôme. C’est donc bien un effet de génération et non de socialisation et qui semble s’engager à partir de la génération des années 50.
Le dernier point met en évidence le prix de la solitude, les foyers solo sont bien moins heureux que les autres comme l’indique la figure (d ). Elle fait aussi apparaître un léger effet en U : la confiance interpersonnelle compte plus quand on est seul ( les bonnes relations de voisinage peuvent compenser le célibat), et lorsque le foyer est nombreux ( le conflit en groupe est un enfer!).
L’exercice ici est largement pédagogique et méthodologiques. D’autres variables doivent être intégrées au modèle, ne serait- ce que la santé, l’intégration sociale qui joue un rôle clé, peuvent être les valeurs, les opinions politiques religieuses. Sa limite est celle d’une première analyse. Elle est aussi celle du pouvoir explicatif des modèles. La confiance à elle seule explique qu’une faible partie de la variance : avec un contrôle par le pays et l’inclusion de la confiance dans l’économie et l’état subjectif de santé, on explique au mieux 24% de la variance. Il reste la place pour d’autre facteurs.
Son intérêt empirique réside dans ce fait intéressant : la très grande stabilité des paramètres du modèle à travers l’espace, le temps, et les catégories sociales, même si l’effet générationnel qu’on vient de mettre en évidence par cette sorte de méta-analyse reste encore à expliquer. Il témoigne pour une forme homéostatique du bonheur qui s’ajusterait aux changements de conditions de vie. Il dépend peu de la confiance envers les institutions, il est plus nettement lié à l’idée que les autres sont bienveillants même si ce lien s’affaiblit avec les générations.
Le propre des êtres autonomes est leur capacité à identifier des signaux et à y répondre de manière adéquate.
L’œil de l’aigle dans le ciel saisit identifier la fourrure fauve dans la prairie jaunie, la luciole reconnait la pulsation lumineuse émise par les partenaire de son espèce, le radiologue le motif d’une structure cancéreuse, l’opérateur radar détermine si le point clignotant sur l’écran correspond à un vaisseau ami ou ennemi. C’est d’ailleurs avec ce problème de radar au cours de la dernière guerre mondiale, que la théorie de la détection du signal a émergé, couvrant des usages nombreux dont le point commun est d’évaluer la qualité d’une décision particulière - le signal reçu correspond-il à une réalité ou à un bruit ? - en établissant un seuil optimum de détection.
Prenons un exemple. Le chien qui aboie devant nous intimide-t-il avant de prendre la fuite ou va-t-il nous attaquer et nous mordre ? En conséquence faut-il lui fracasser le crâne avec le bâton qu’on tient en main, ou rester immobile jusqu’à ce qu’il se soit éloigné?
L’intensité de l’aboiement est le signal que nous devons traiter.
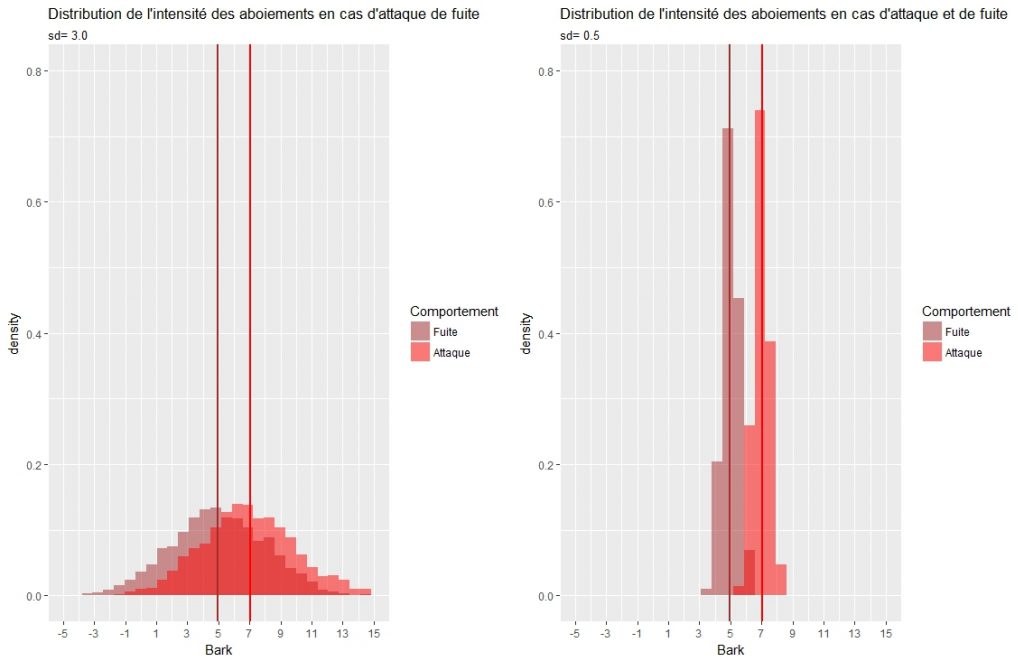
Pour bien se représenter le problème, nous générons un exemple hypothétique. On suppose que les attaques correspondent à des aboiements d’intensité 7 en moyenne, et la fuite de 5. Deux situation sont traitées : l’une où l’écart-type des aboiement est de 0.5, l’autre de 3. Ce qui est représenté dans la figure 1.
On a le réflexe avec ce type de donnée d’effectuer un test statistique, celui du test de student est largement suffisant, dans les deux situations. Il nous permet de décider pour un risque de première espèce donné, de rejeter l’hypothèse nulle d’égalité des moyennes et par conséquent de conclure que les moyennes sont distinctes et que, dans notre cas, que les décisions sont bien associées à l’intensité du signal. Dans notre exemple ( cas de la figure de gauche à forte variance) les moyennes empiriques sont de 5, 06 et 7,04, et le test t de student a une valeur critique de 26. La probabilité que les moyennes empiriques diffèrent alors qu’elle sont égales en réalité est quasi nulle, bien en-deça du risque usuel de 5%. Ce test cependant ne dit pas comment agir, autrement dit à partir de quelle intensité faut-il se préparer à frapper le chien fou furieux, ou ne pas agir. Il dit juste qu’il y a une différence.
On remarque cependant que lorsque les deux distributions sont bien différenciées, il est plus simple de discriminer les deux signaux. En choisissant une valeur supérieure à 6 (diagramme de droite), il y a très peu de chance de frapper cruellement la bête alors qu’elle va s’enfuir, et de se laisser mordre parce qu’on a cru a tors qu’elle enfuirait. Mais quand les distributions se superposent largement (diagramme de droite), comment pour une valeur donnée de l’aboiement décider de l’action à mener? Quel seuil se donner? L’analyse ROC va permettre de répondre à la question, mais avant poursuivons sur cette question de superposition et de discrimination du signal.
Une mesure pour ceci a été proposée depuis longtemps: la sensitivité ( ou discriminance) Elle est notée d’ et se définit par
d’=d/s
où d est la différence des moyennes des deux signaux et s la variance moyenne des signaux ( racine²(1/2(Sda²+Sdf²)). Dans le premier cas, on obtient une valeur d’ de 0,67 dans le second de 4, donc 12 fois plus forte dans la partie droite de la figure 1.
Le problème reste entier. Quelle valeur retenir pour décider l’action a entreprendre (frapper ou rester immobile) ? A partir de quel seuil doit-on interpréter l’aboiement comme un signal d’attaque?
Pour évaluer cette valeur, il suffit de compter d’une part le nombre de bonne décisions, et d’autre part les mauvaises décisions. On comprend de suite que deux types d’erreurs peuvent se produire :
On peut conclure que le chien va attaquer alors qu’il ne fait qu’intimider. Le résultat de l’action est que le chien va se prendre un coup de bâton sans raison. C’est le prix d’une fausse alarme.
On peut aussi conclure qu’il ne va pas attaquer, alors qui bondit et nous mord au mollet. L’alerte est ratée, le signal est sous-interprêté, on sera bon pour un vaccin anti-rabique, et quelques soins à l’hôpital.
Plus précisément le problème peut se formuler sous la forme du tableau suivant
A partir du tableau différents indicateurs peut être construits, on remarquera rapidement qu’on retrouve les classiques de l’évaluation du machine learning : précision , recall et accuracy. A vrai dire c’est le même problème. Comment évaluer la capacité d’un modèle à discriminer des signaux.
Le taux de vrai positif ( ou recall, ou sensitivy) est égal à TP/P . Il donne la proportion de bonnes détection sur le total des détections positives. S’il est élevé, le détecteur donne trop souvent de fausse alertes.
le taux de faux positif : FP/N
taux de vrai negatif ( ou spécificité) : FN/N
L’accuracy ( précision) donne la proportion de bonne prédiction : TP+TN/(P+N)
l’erreur en est le complément : 1- Acc = (FP+FN)/P+N
F : c’est la moyenne harmonique de la précision et du recall. c’est un indicateur de synthèse
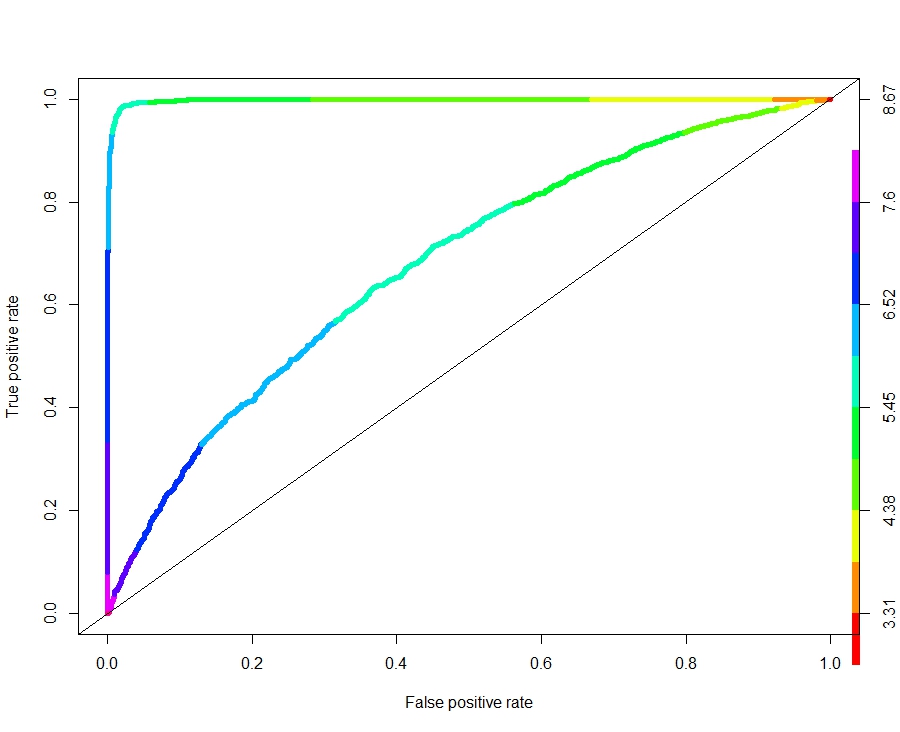
L’invention des contrôleurs de radars est de représenter ces performances sous la forme d’un diagramme appelé Receiver Operational Characteristics (ROC)construit en calculant pour différents seuils de décision ( l’intensité des aboiement) le taux de faux positifs et en ordonnée le taux de vrais positifs. Les deux courbes (On utilise le package RORCde r - l’ensemble du code est sous le post) de la figure suivante correspondent aux deux situations (faible et forte discriminance), la diagonale correspond à une situation de non discriminance. La courbe la plus coudée correspond au signal le moins ambigu (Sd=0.5).
La lecture du ROC est simple : plus la courbe est coudée et meilleur est le modèle ( ou le signal est peu bruité). Les couleurs représentent différents seuils. Le violet et le bleu correspondent au seuils les plus élevés. En lisant le diagramme on s’ aperçoit que pour accroitre le taux de vrai positif il faut concéder une proportion croissante de faux positifs. Dans le cas du “bon” modèle ceci se produire à partir d’un taux de vrai positif de plus de 90%. Dans le cas bruité, il faudra accepter un taux de l’ordre de 60% de faux positifs pour identifier 8% des vrais positifs. Quel est donc le bon trade-off?
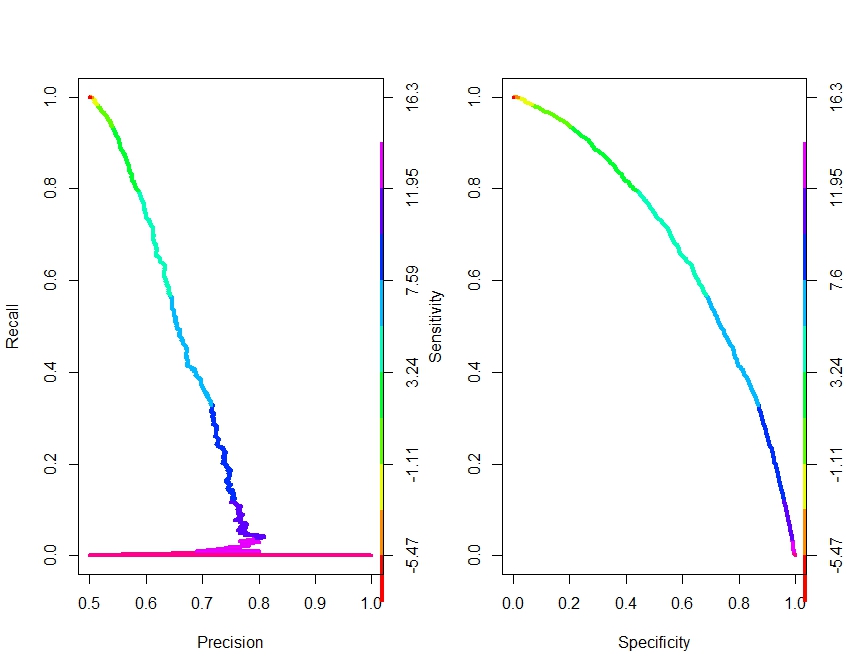
On peut reproduire des représentations analogues avec les autres indicateurs. On a inclus ainsi le diagramme specifité/sensitivité, et bien sur le couple precision/recall bien connu des machine learners. RORC en propose de nombreux autres. Il y en a pour tous les goûts.
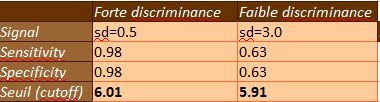
La détermination du seuil optimal, qui combine la plus grande proportion de signaux bien reconnus tout en minimisant l’erreur des faux positifs, suit le principe de retenir le point le moins éloigné de la situation de discrimination parfaite : 100% de taux de vrais positifs et 0% de faux négatifs. RORC automatise ce calcul par une fonction simple qui nous donne les résultats suivants.
On s’aperçoit ainsi que le seuil optimal est plus faible (5,91) dans le cas d’un signal bruité (faible discriminance) que dans celui d’un signal clair (6.01). La stratégie est donc d’être plus prudent et d’augmenter le seuil d’alerte quand le signal est ambigu.
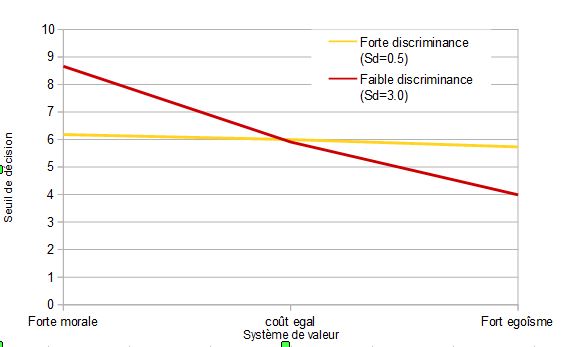
Dans ce calcul, un facteur décisif et économique, les coûts de l’erreur, ne sont pas pris en compte. Le coût des faux positifs - penser que le chien va attaquer, alors qu’il ne le fera pas - est un coût moral. Si on milite pour l’antispécisme, qu’on considère que la douleur imposée à l’animal est criminelle, qu’on ne mérite pas de circonstances atténuantes due à la peur, ce coût sera élevé. Il peut être consacré par le droit et se traduire par de fortes amendes si ce n’est des peines de prison. Le coût des faux négatifs est celui de se faire mordre, il est moins ambigu et il se traduit par celui d’une visite à l’hôpital pour le vaccin anti-rabique et couturer la blessure.
Une autre fonction de RORC permet d’analyser ces options en fixant un coût pour les faux négatifs et les faux positifs. On va donc calculer les seuils en envisageant deux situations qui s’ajoutent à l’analyse précédente où ces coûts sont considérés comme équivalents.
Forte valeur morale : On fixe à 1 le coût des faux négatifs et à 5 celui des faux positifs (il est 5 fois plus coûteux de frapper le chien que de se faire mordre)
Fort égoïsme : On fixe à 5 le coût des faux négatifs et à 1 celui des faux positifs ( il est 5 fois moins coûteux de frapper le chien pour rien que de se faire mordre).
Le résultat apparait dans la figure suivante. On s’aperçoit que lorsque le signal est clair (forte discriminance) la moralité a peu d’influence, on retient un seuil un peu plus bas en cas d’égoïsme, à peine plus élevé quand on partage des valeurs antispécistes. Ces valeurs sont équivalents. Lorsque le signal est ambigu ( faible discriminance), on passe en revanche du simple au double. Le poids de la morale impose un seuil très élevé (8.66), celui de l’ego-préservation l’effondre de moitié (3.91). Deux stratégies totalement différentes émergent, pas tant par le calcul, mais par son imprécision ! Quand le modèle discrimine mal, l’impact des coûts, dont la valeur est fixée indépendamment du modèle, sur le seuil de décision est considérable.
Notre petite histoire de chien (en hommage au musée de la chasse dont l’objet est bien la détection) avait d’abord un but pédagogique et servira à nos étudiants ( ceux de marketing y trouveront une bonne manière d’améliorer leur connaissance des méthodes de scoring et de leurs évaluations). Elle a aussi sa leçon morale et politique.
L’opérationnalisation d’un modèle de décision - la détection d’un signal en est une variété - ne consiste pas simplement à faire des prédictions. Elle conduit à choisir des normes pour établir la décision. Les valeurs de ses normes sont externes au modèle. On frappe le chien, pas seulement parce qu’il aboie, mais parce qu’on identifie de manière imprécise cet aboiement, et que dans cette incertitude on privilégie son propre intérêt, à moins d’être soumis à une autre norme, celle de la vie du chien. Et le modèle ne décide pas de ce choix. Il l’accuse quand il est imprécis. Autrement dit ils pourraient être neutre quand il sont précis, mais quand il ne le sont pas, ils traduisent des choix politiques et moraux.
Pour donner une idée plus concrête prenons la question de l’octroi de crédit à la consommation. Noter les consommateurs sur une échelle de risque ( risk scoring) ne porte pas directement à conséquence pourvu que le modèle soit construit convenablement : sur des échantillons représentatifs (sans biais de sélections, ce cancer du big data) et avec une bonne spécification ( sans biais du même nom) . Ce peut être un modèle logit qui fournissent un score sous la forme d’une probabilité de défaillance à rembourser ou pourquoi pas quelque chose de beaucoup plus sophistiqué. Sa mise en œuvre requiert une étape supplémentaire : fixer le seuil qui amènent à considérer un mauvais crédit. A quel niveau doit-on refuser le prêt? Si le risque est supérieur à 5%? ou 10%? ou 20% ?
Ce seuil dépend non seulement de la qualité du signal à traiter (le profil du demandeur de crédit qui va se résumer en un score qui discrimine les bons et les mauvais risques) mais aussi par l’introduction de coûts associés à l’erreur qui prend un double visage. Le faux négatif c’est accorder un crédit à quelqu’un qui ne le remboursera pas, et son coût le montant perdu. Le faux positif c’est refuser un crédit à quelqu’un qui l’investira dans une startup nommée Facebook et qui vaudra 600 milliards. Les banques généralement comptent le premier risque et pas le second. On pourrait imaginer un monde où les emprunteurs opposent les opportunités perdues à celui qui leur a refusé un crédit.
Dans un monde de donnée qui se prépare à envahir le monde avec le machine learning et les nombreuses familles de modèles prédictifs, infiltrant dans tous les processus des micro-mécanismes de détection et de décision, il y a toute les chances que les modèles restent imparfaits car ce monde reste un monde social, où les corrélations sont généralement faible, au contraire d’un monde physique plus déterministes. Cette imperfection par nature risque d’amplifier l’effet des systèmes de valeurs, qui se traduit dans l’évaluation des coûts des erreurs, sur la détermination des seuils de décision.
Annexe code - largement inspiré de https://www.r-bloggers.com/a-small-introduction-to-the-rocr-package/ -
Que fait-on sur les réseaux sociaux? Quels bénéfices y trouve-on? Quelles gratifications y obtient-on? Les fréquente-t-on parce qu’ils nous donnent des opportunités ou parce qu’ils noient l’ennui? Y va-t-on parce qu’on est malheureux ou parce qu’on est heureux ?
A vrai dire on en sait assez peu. L’étude Wave est sans doute la plus étendue par le nombre des nations qu’elle étudie, mais peut être pas totalement convaincante sur sa méthodologie. L’univers académique néglige cette question pratique préférant des thèses plus audacieuses, ou l’étude de comportements déviants ou périphérique. Et d’ailleurs ce serait bien de l’analyser systématiquement nous savoir quelles dispositions elle met en évidence.
Un jeu de données produit par une des mes étudiantes de master va nous permettre d’aborder la question au moins sur le plan de la méthode. Son jeu de donnée (260 individus) est représentatif du cercle social d’une étudiante franco- russe qui aura recueilli dans une population majoritairement jeune et étudiante les réponses à trois questions :
Quels sont les réseaux que les gens utilisent et avec quelle fréquence ?
Quelles y sont leurs activités et les gratifications qu’ils en retirent : une batterie de 36 items est exploitée à cette fin
Etes-vous heureux dans la vie ? C’est une approche du concept de Customer Well Being qui semble recueillir un intérêt de plus en plus grand dans la littérature académique.
L’approche ici reste descriptive. Le plus c’est de segmenter sur une base très traditionnelle, mais fondamentale, quels sont les avanatges que recherche les utilisateurs de réseaux sociaux dans l’usage de ces réseaux? La question subsidiaire c’est de comprendre comment ces usages sont liés à leur qualité de vie.
Commençons par le début et par l’analyse des réseaux qu’ils emploient. deux critères sont mis en avant, le sexe et la nationalité. L’un reflète un ordre social qui se perpetue dans la construction du genre, l’autre au moins une différence culturelle façonné par l’histoire, les conditions économiques et sociales. En deux graphiques on y observe qu’il y a peu de différence de genre, mais des spécificités nationales importantes. Si Facebook est dominant en france, c’est vcontack qui semble exploiter la même niche en russie.
Ces dernières années les progrès du text mining renouvellent largement l’étude des contenus textuels.
Un saut a été franchi depuis les techniques classiques d’analyse factorielles des correspondances. Les outils récents inspirés du ML peuvent remplacer ou au moins compléter les bonnes vieilles techniques de l’analyse lexicale.
Alors plutôt que de faire des Sudoku pendant les vacances, autant se balader dans les packages de r et d’appliquer ces techniques à un cas pratique. Pourquoi ne pas explorer justement ce que l’on dit de ces techniques sur les réseaux sociaux. Que dit-on de l’intelligence artificielle et du machine learning ? Quels en sont les sujets de conversation?
Commençons par le début. Il nous faut un corpus. Autant le prendre là où il est facile à capturer, c’est à dire dans Twitter.
La première étape consiste à créer un compte sur l’API (REST), pour pouvoir extraire ce que l’on souhaite ( avec des limites imposées par twitter). Et lLa seconde étape consiste simplement à se connecter à l’API, via r, et à lancer une requête. Ce qui se fait de manière simple avec le code suivant :
#accès à l api de twitter
consumerKey<-"Xq..."
consumerSecret<-"30l..."
access_token<-"27A..."
access_secret<-"zA7..."
setup_twitter_oauth(consumerKey, consumerSecret, access_token,access_secret)
Pour rechercher les tweets, on échantillonne sur plusieurs variantes de hashtag, en préférant la méthode des twits les plus récents (une alternative proposée par Twitter est de choisir les plus populaires, une troisième méthode mixant les deux approches). Il suffit ensuite de fusionner les fichiers, puis de dédupliquer les enregistrements identiques.
#recherche des twits avec plusieur requetes
tweets1 <- searchTwitter("#IA", n = 2000, lang = "fr", resultType = "recent", since = "2017-08-01")
tweets2 <- searchTwitter("#ML", n = 2000, lang = "fr", resultType = "mixed", since = "2017-08-01")
tweets3 <- searchTwitter("#AI", n = 2000, lang = "fr", resultType = "recent", since = "2017-08-01")
tweets4 <- searchTwitter("#MachineLearning", n = 2000, lang = "fr", resultType = "recent", since = "2017-08-01")
tweets5 <- searchTwitter("#Deeplearning", n = 2000, lang = "fr", resultType = "recent", since = "2017-08-01")
#transformer en data frame
tweets_df1 <- twListToDF(tweets1)
tweets_df2 <- twListToDF(tweets2)
tweets_df3 <- twListToDF(tweets3)
tweets_df4 <- twListToDF(tweets4)
tweets_df5 <- twListToDF(tweets5)
tweets_df <- rbind(tweets_df1,tweets_df2,tweets_df3,tweets_df4,tweets_df5)
Le décompte se faisant tout les quarts d’heure, on peut répéter l’opération pour récupérer quelques dizaines de milliers de tweets en quelques heures. Et si l’on a un peu de budget on changera d’Api pour streamer en temps réel ce que l’on souhaite.
On dispose donc d’un corpus d’environ 6000 tweets, dont il va falloir nettoyer le contenu. C’est l’opération la plus difficile, elle demande de l’astuce et une bonne compréhension des contenus. Dans notre cas, différentes opérations vont être menées et elles constituent l’étape essentielle où l’astuce de l’analyste est la clé de l’analyse.
Il faut aussi éliminer les liens URL, mais aussi les mentions
De même les nombres, la ponctuation, mettre en minuscule
Certains termes risque de n’apporter aucune information, les mots de liaisons, les articles, et naturellement les termes qui ont permis la sélection ( #IA par exemple)
et enfin réduire les termes à leurs racines pour éviter une trop grande fréquences de termes équivalents mais distincts ( poisson, poissonier) c’est l’opération de stemming qui identifie la racine du lexique constitué.
#recherche des twits avec plusieur requetes
# creation du corpus et nettoyage du texte
tweets_corpus <- Corpus(VectorSource(tweets_text))
removeURL <- function(x) gsub("http[[:alnum:][:punct:]]*", "", x) #enlever les liens
tweets_corpus <- tm_map(tweets_corpus, content_transformer(removeURL)) #enlever les liens
removeACC <- function(x) gsub("@\\w+", "", tweets_corpus) #enlever les comptes
tweets_corpus <- tm_map(tweets_corpus, content_transformer(removeACC)) #enlever les comptes
tweets_corpus <- tm_map(tweets_corpus, removeNumbers) #enlever les nombre
tweets_corpus <- tm_map(tweets_corpus, removePunctuation) # ici cela va supprimer automatiquement tous les caractères de ponctuation
tweets_corpus <- tm_map(tweets_corpus, content_transformer(tolower)) #mettre en minuscule
tweets_corpus <- tm_map(tweets_corpus, removeWords, stopwords("french")) #supprimer automatiquement une bonne partie des mots français "basiques"
tweets_corpus <- tm_map(tweets_corpus, stripWhitespace) # ici cela va supprimer automatiquement tous les espaces vides
tweets_corpus <- tm_map(tweets_corpus, stemDocument, language = "french") #on cherche les radicaux des termes
tweets_corpus <- tm_map(tweets_corpus, removeWords,c("ai", "machinelearning","ia","ml", "deeplearning","rt")) #enlever le terme commun
tdm <- TermDocumentMatrix(tweets_corpus, control=list(wordLengths=c(5, 30))) #creation de la matrice termsXdocuments
On conduit cette opération avec les ressources du packagetm qui est le véritable moteur du text mining. C’est une opération très empirique, la procédure se construit de manière itérative, en prenant soin de bien séquencer les différentes actions. Et il sera particulièrement utile de regarder ce que font les autres data-scientists, leurs astuces et les élégances de langage qu’ils emploient. C’est l’étape la plus difficile, d’un point de vue technique mais aussi pragmatique.
La première commande transforme le fichier de données dans un format particulier qui est celui qui décrit le corpus. Chaque enregistrement est codé sous la forme d’un triplet : le terme ( un mot racine), le document ( un tweet) et la fréquence d’apparition du terme dans le document. Pour l’utilisateur d’un logiciel statistique classique, SPSS, c’est l’élément le plus troublant, r ne fonctionne pas simplement avec des tableaux individusXvariables, ses objets sont beaucoup plus subtils, complexes mais pratiques. Les commandes précedentes effectuent les transformations requises du corpus. La dernière crée la matrice termes document que nous voulons étudier.
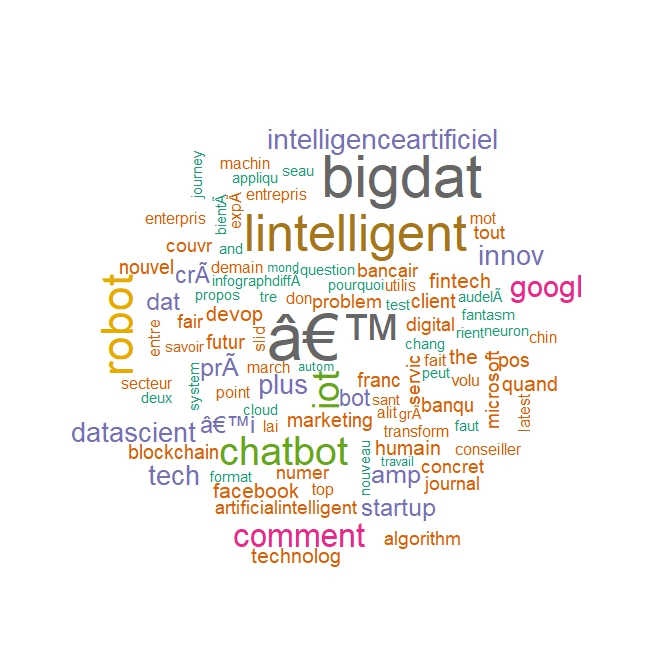
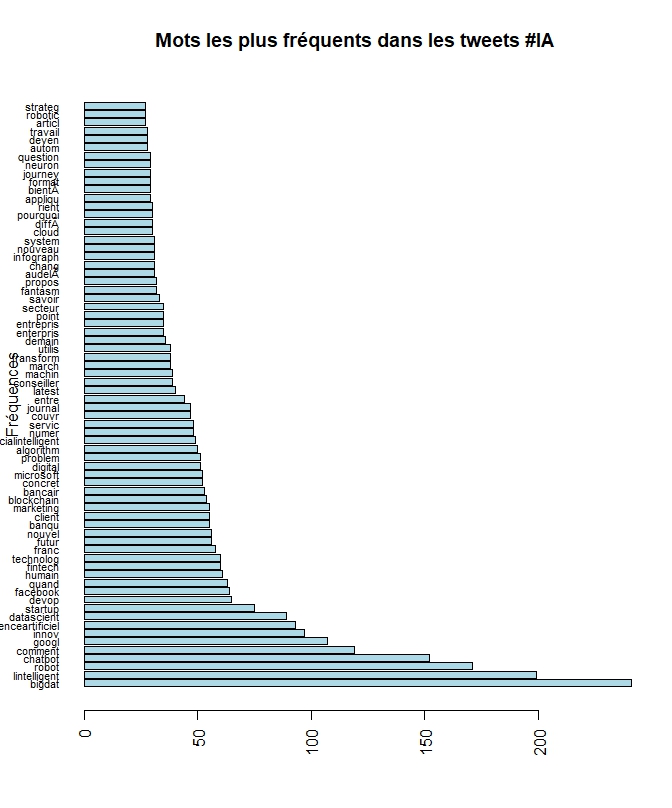
Comme à l’ordinaire, débutons par le plus simple : quels sont les termes les plus fréquents? A cette fin, deux technique peuvent être employées. La première est simplement la représentation ordonnée par la fréquence des termes, la seconde, très visuelle est de produire une représentation très populaire, celle des nuages de mots. En fonction de ces résultats on pourra réitérer les opérations précédentes et ajuster le jeu de données et sélectionner les termes que l’on veut analyser. En voici le code et les résultats.
cloudword
FréquenceMot
dim(tdm)
nTerms(tdm)
m <- as.matrix(tdm)
v <- sort(rowSums(m), decreasing = TRUE)
d <- data.frame(word = names(v),freq = v)
head(d, 350)
barplot(d[1:70,]$freq, las = 2, names.arg = d[1:70,]$word,
col ="lightblue", main ="Mots les plus fréquents dans les tweets #IA",
ylab = "Fréquences", horiz=TRUE, cex.names = .7)
x11() #pour ne pas ecraser le chart precedent
set.seed(123456)
wordcloud(tweets_corpus, max.words = 100, colors = brewer.pal(8, "Dark2"))
Les choses sérieuses viennent maintenant avec l’utilisation d’une méthode de modélisation des topics. On emploie ici le package ModelTopics et la méthode LDA ( Latent Dirichlet Allocation) , qui cherche à calculer la probabilités qu’un terme appartienne à un Topic, et qu’un topic appartiennent à un document, en ne connaissant que l’appartenance des termes aux document. L’idée est de prendre en compte que chaque document est un mélange de topic, et que chaque topic est un mélange de mots. On en trouvera une excellente présentation ici dont nous avons repris des éléments de code, pour une présentation plus technique la page Wikipedia est un bon début.
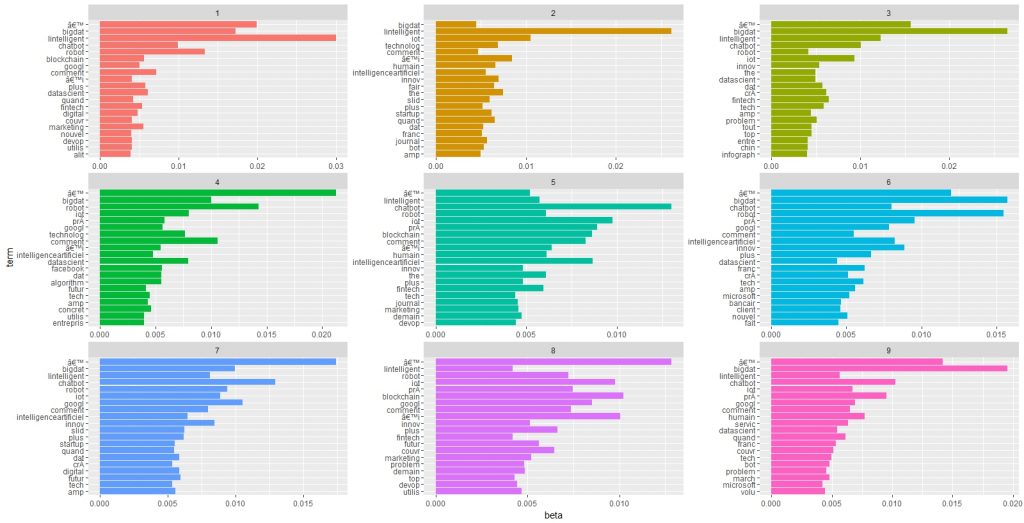
Le résultat principal est constitué par le diagramme suivant qui représente pour chaque topic ( on a choisit d’en identifier 9 de manière avouons le arbitraire - la question de la détermination du nombre optimum n’est pas encore résolue). Les valeurs sont les probabilités ( beta) que les termes soient associés aux topics. C’est une sorte de spectre lexical. Le topic 5, par exemple semble être relatifs aux chatbots, à l’IoT et à ses applications en marketing et dans les fintech.
Avouons- le l’interprétation n’est pas évidente. Nous avons besoin d’un nettoyage plus poussé et sans doute de jouer encore plus sur les paramètres du modèle qui consistent d’abord dans le nombre de sujets (topics) qui mérite sans doute d’être plus élevés, et dans un paramètre Alpha qui ajuste le nombre de mots associés aux sujets. Encore mieux, il serait bon d’implémenter le package Ldavis qui produit une visualisation remarquable.
On pourrait aller encore plus loin en considérant ce premier modèle comme un modèle d’entrainement, puis en l’utilisant pour classifier de nouveaux documents. Ainsi, imaginons d’extraire chaque jour un nouveau jeu de données, on peut imaginer construire un outils qui donne l’évolution des thématiques dans la conversation des réseaux-sociaux. Il nous suffira de la commande suivante :
test.topics <- posterior(train.lda,test)
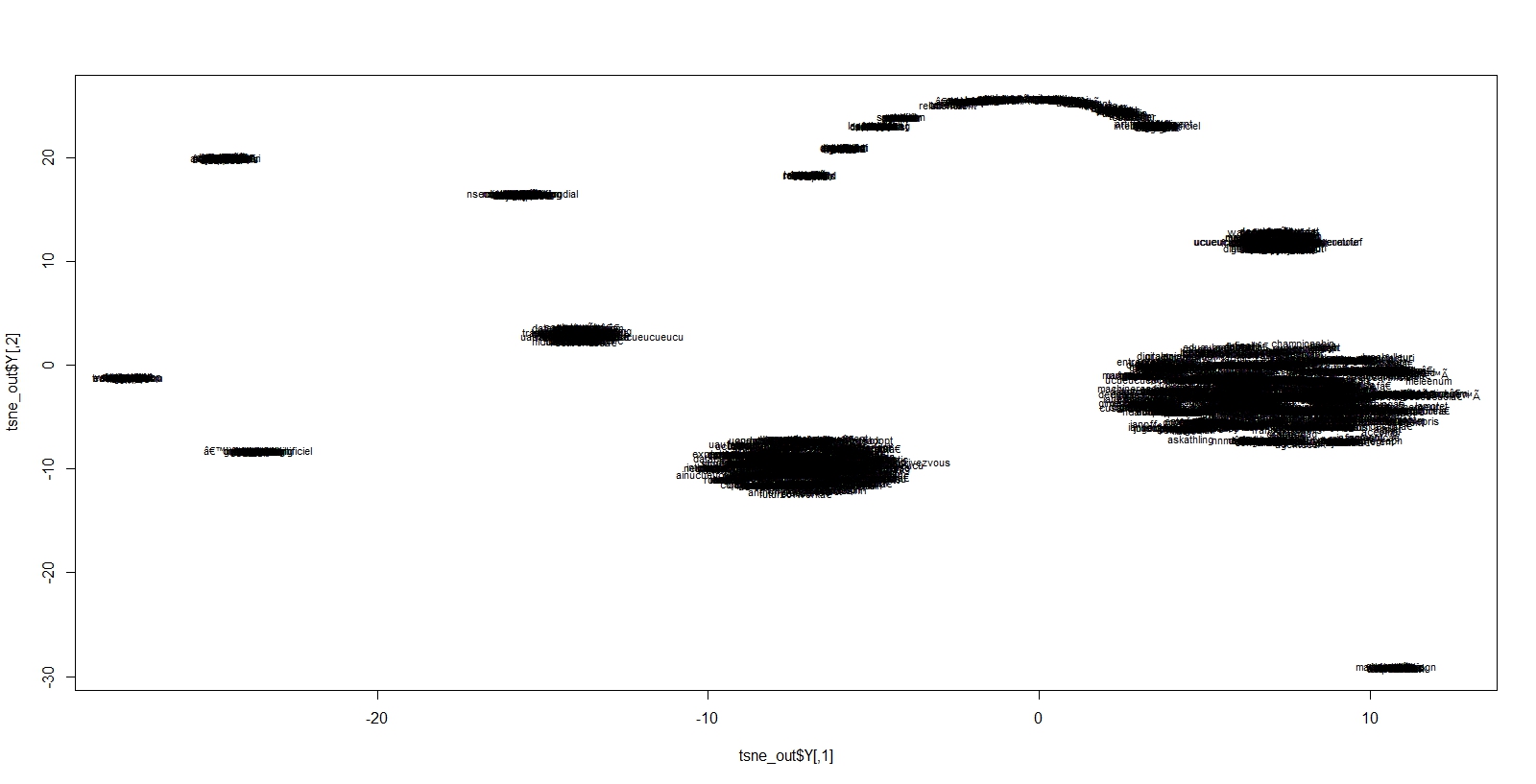
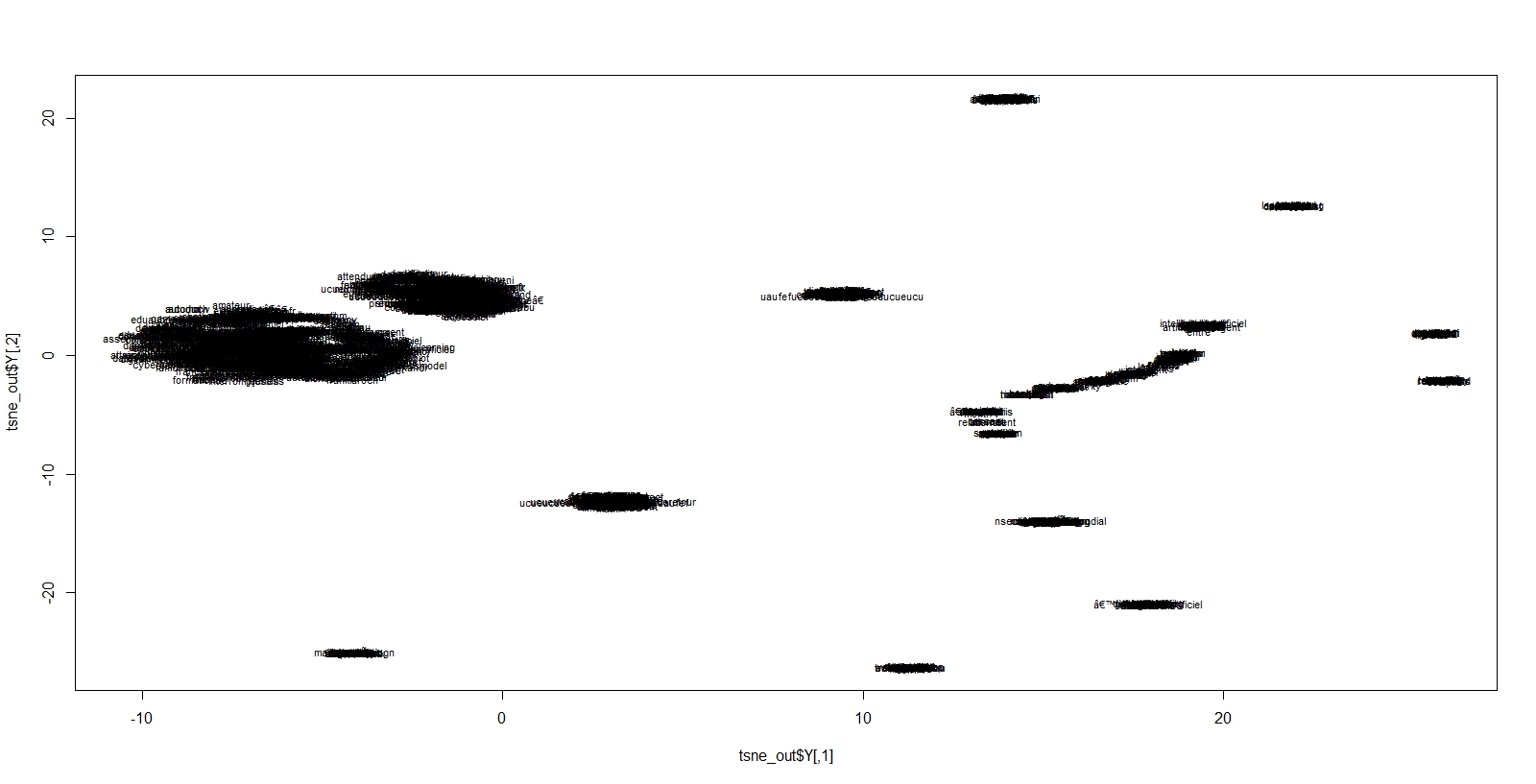
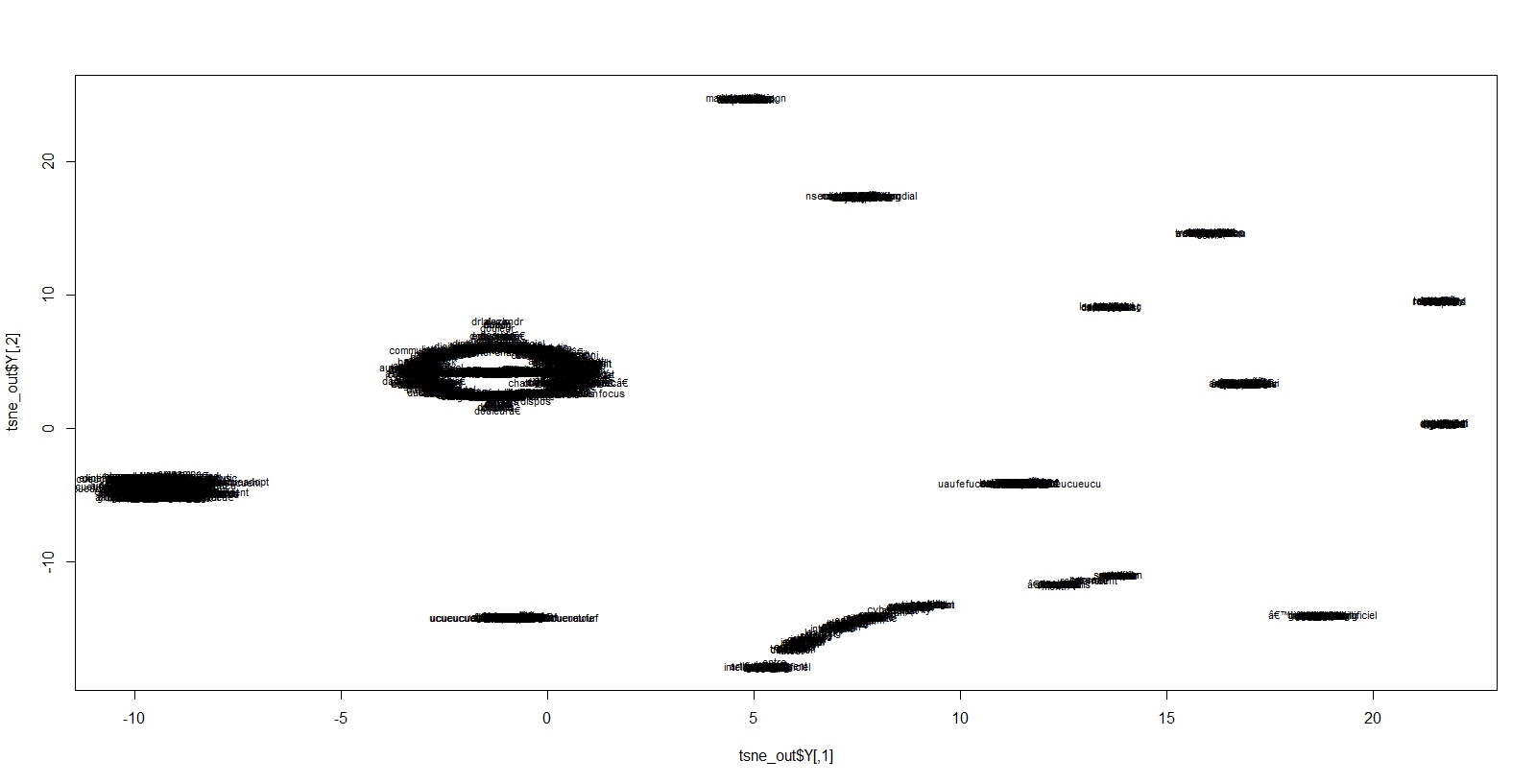
Une autre approche est celle de la méthode Tsne, fournit par le package Rtsne. C’est finalement une sorte d’analyse des similarités, à la manière du MDS ( Multi Dimensionnal Scaling) mais qui mets en jeu des calculs de distances très particulier, dont la vertu principal est de rendre compte de niveaux d’échelles différents. Ce qui est très proche sera plus ou moins éloignés, ce qui est loin est plus ou moins rapprochés. On échappe au phénomène de dégénérescence du vieux MDS, et à une meilleure représentation quand les objets sont éloignés. On contrôle ceci par un paramètre de perplexité, qui reflète sommes toute le nombre de voisins pris en compte dans les calculs. On lira ceci pour mieux en comprendre les effets.
En voici les résultats pour plusieurs degrés de perplexité. La représentation est illisible ( il y a environ 4000 termes) mais des groupes de mots bien distincts apparaissent. Elle va nous servir de base pour une meilleure visualisation de cet espace.
perplex30
perplex15
perplex5
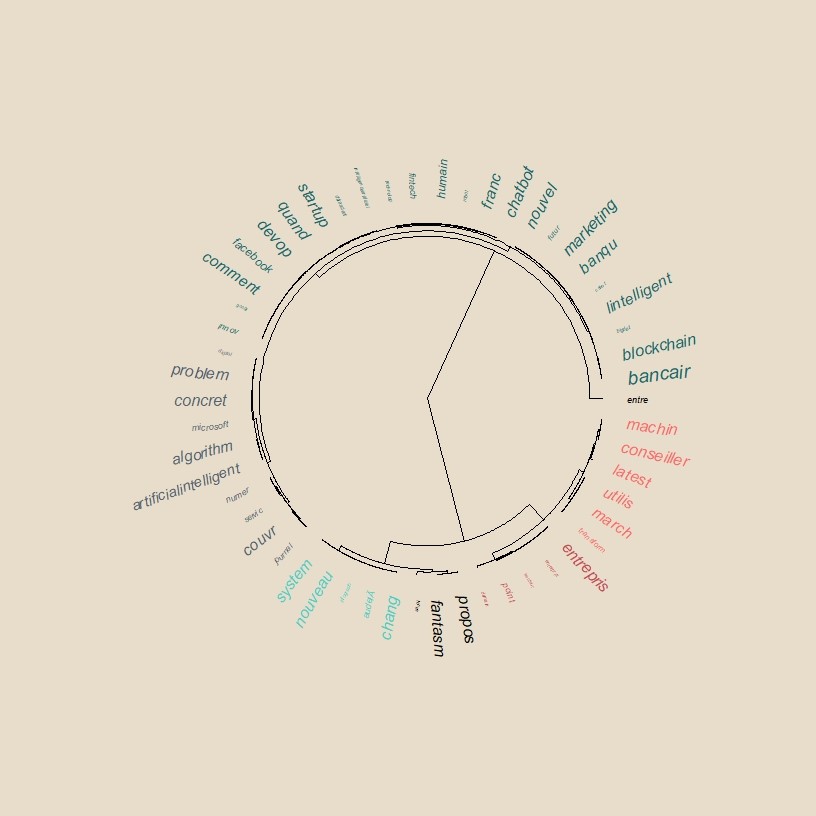
Un modèle avec une perplexité de 20 et à 2 dimensions est choisi comme base d’une meilleure visualisation. On va se concentrer sur les termes les plus fréquents et l’on applique une méthode de classification (méthode de ward) dans l’espace définit par tsne, et avec un peu de code supplémentaire, on produit un dendogramme radial produit par le package Ape, dans lequel la taille relative des termes est proportionnelle à leur fréquence et les couleurs correspondent à un découpage en 7 classes.
X1<-tsne_out$Y[,1]
X2<-tsne_out$Y[,2]
Fq<-rowSums (tdmdata, na.rm = FALSE, dims = 1)
Rtsne<-data.frame(Fq,X1, X2)
Rtsne2 <- subset(Rtsne, subset=Fq>30, select=c(X1,X2))
#clustering
m2 <- as.matrix(Rtsne2)
distMatrix <- dist(scale(m2))
fit <- hclust(distMatrix, method = "ward.D2")
p<-plot(fit)
rect.hclust(fit, k = 7) # cut tree into 7 clusters
library(ape)
plot(as.phylo(fit), type = "unrooted")
plot(as.phylo(fit), type = "fan")
# vector of colors
mypal = c("#556270", "#4ECDC4", "#1B676B", "#FF6B6B", "#C44D58")
# cutting dendrogram in 7 clusters
clus = cutree(fit, 7)
# plot
op = par(bg = "#E8DDCB")
# Size reflects frequency
plot(as.phylo(fit), type = "fan", tip.color = mypal[clus], label.offset = 1, cex = log(Rtsne$Fq, 10), col = "red")
Voici le trail! On y lit plus clairement les sujet : on peut commençant en descendant à droite par un premier thème sur les chatbots et de Facebook naturellement qui se poursuit sur une thématique marketing et bancaire, les applications. Le troisième thème, en rouge est plus centré sur l’entreprise et l’organisation, l’impact sur les conseillers. Les thèmes du fantasme et du changement nécessaire s’enchaîne assez logiquement, un sixième thème se centre sur la résolution de problème, le dernier est relatif aux questions entrepreuneuriales et aux start-up.
On aura condensé ainsi un contenu brut de 7000 tweets et 4000 mots en une image.
La dramaturgie présidentielle est pour cette première semaine de campagne particulièrement inquiète.
Le risque que le Front National parvienne à la tête de l’état, les rancoeurs ou le calcul au Parti de Gauche, les coups de com et la fébrilité médiatique ajoutent à l’anxiété. La nouveauté de la configuration incite à la plus grande prudence mais puisque certains diffusent l’angoisse sourde d’une France rancie en brandissant le risque de l’abstention, autant revenir au calcul. Les sondages ne sont pas si mauvais et d’une bonne aide. Le premier tout l’a prouvé.
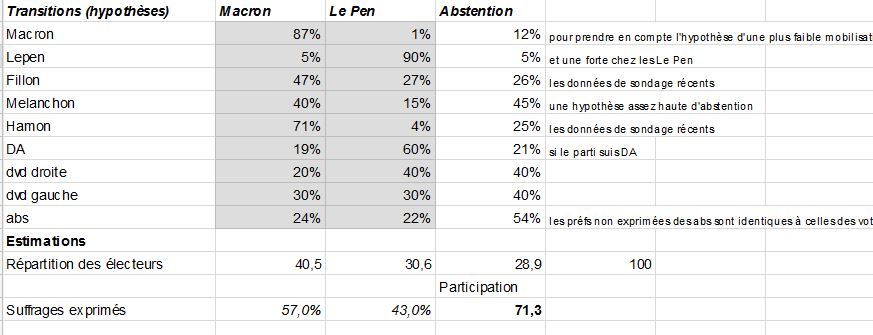
Pour évaluer le résultat, on peut le faire directement, les sondages annoncent Macron avec de 58 à 62%, on peut aussi faire un calcul de prise de parts de marché qui consiste simplement à multiplier le vecteur de la répartition des votes ( et nous y incluons les abstentionnistes du premier tour) par une matrice de transition dont les sondages nous donnent une idée de la valeur de ses éléments et qu’on peut alimenter par différentes hypothèses en alternant ses valeur en faveur de l’un ou l’autre des candidats. Compte-tenu de la nature de l’élection on considère ici l’abstention comme une option de choix pertinente. Pour le lecteur qui veut jouer les éléments sont accessibles sur cette feuille (il suffit de modifier les valeurs dans la zone grisée).
Le résultat est clair : en prenant des hypothèses pessimistes pour Emmanuel Macron, on arrive à une victoire avec 57%. Si en revanche si ceux qui ont voté Mélenchon, au lieu de voter Macron pour 40% d’entre d’eux étaient 65% ( ils seraient alors 20% à s’abstenir au lieu des 45% qui en ont exprimés l’intention ces jours ci), le score monte à 59%. Comme on essaiera d’affiner en fonction des informations nouvelles on indiquera ici, les corrections successives du modèle.
le 1er mai à 13:50 : Evolution des reports de voix de Dupont-Aignan depuis Vendredi #OpinionWay Macron 44% (+13) Le Pen : 31% (-6) Abstention : 25% (-7) -> donc 58,5% pour Macron et 41,5 pour LePen (le même sondage donne 61% en question directe)
On rejoint les sondages plus directs. Ici le calcul est minimal, on devrait aller un peu plus loin et prendre ces éléments comme l’a priori d’une approche plus bayésienne que nous avons esquissée dans le post précédent en simulant des centaines de scénarios (modèle de dirichlet).
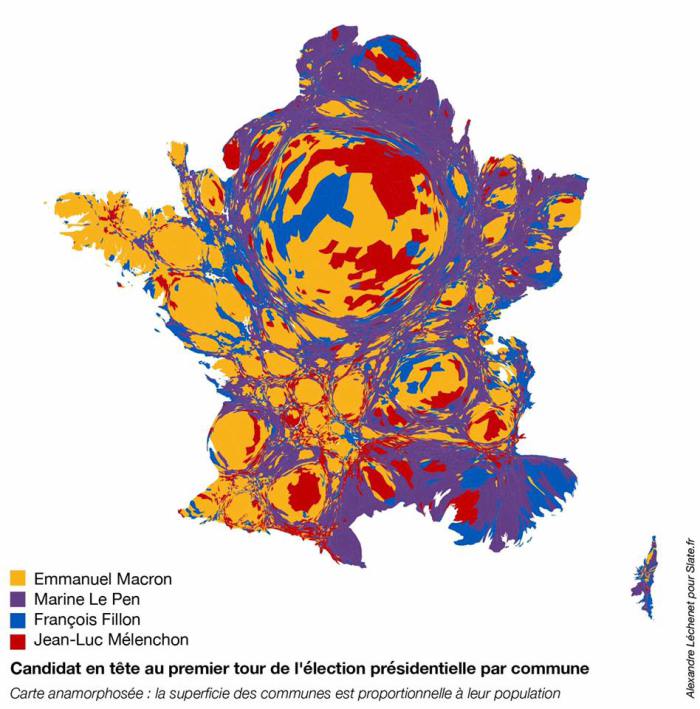
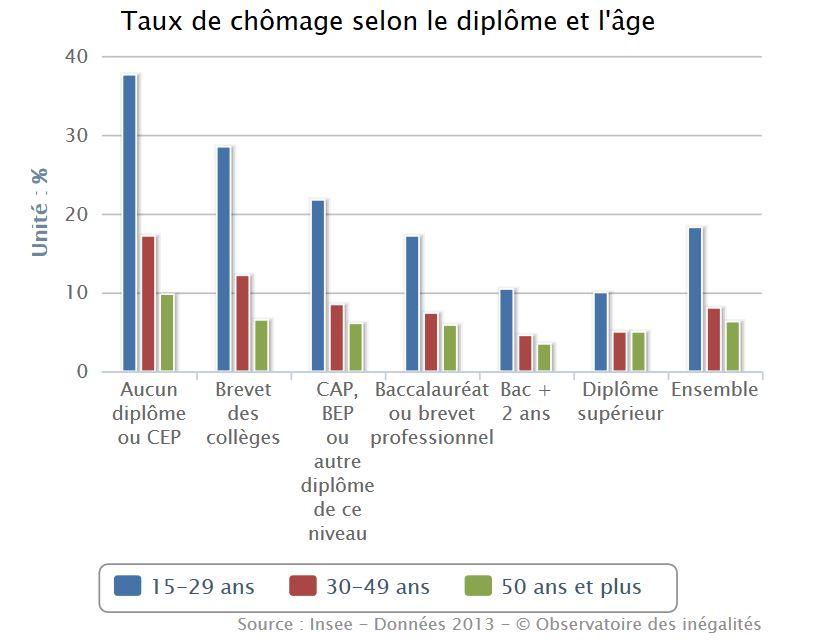
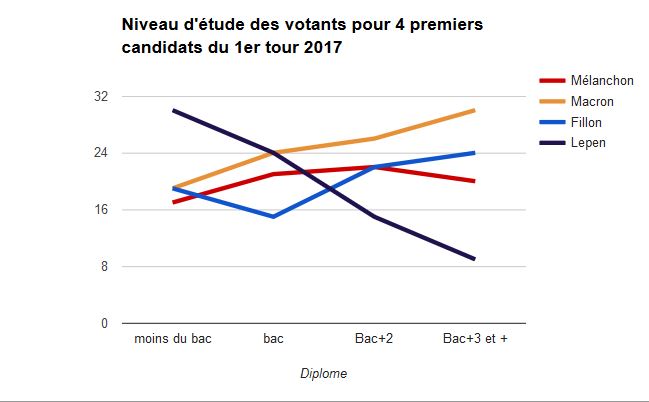
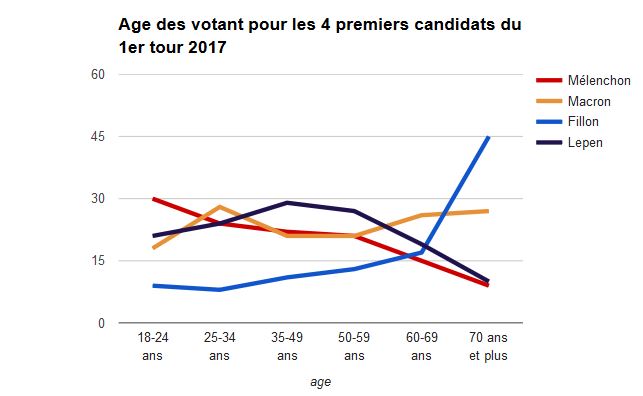
Mais restons en au problème de segmentation. On a beaucoup commenté une France coupée en deux socialement et géographiquement, en prêtant à ces catégories beaucoup d’affect. Une enquête d‘Ipsos-Steria donne des éléments intéressants. Nous avons sélectionné deux critères qui semblent les plus discriminants au regard d’un indicateur très simple : le rapport de la fréquence maximale sur la fréquence minimale. Il s’agit de l’âge et du niveau de formation. Tous les autres critères socio-démographiques ont des valeurs inférieures.
Chomage en fonction de l'âge et du Diplôme
diplome vote
age vote
prévisionbasesondagedivers1ermai
L’age distingue l’électorat de Fillon dont le score est inférieur à 15% chez les moins de 65 ans et bondit à 45 chez les plus de 70 ans. Une population dans laquelle d’ailleurs Macron réussit bien. Les anciens rejettent les extrémismes mêmes s’ils restent majoritairement conservateurs. Le ratio est ici de 5,6 : les plus de 70 ans sont 5,6 fois plus nombreux que les plus jeunes (45% pour 8%). On notera aussi que Mélenchon a remporté la bataille de la jeunesse, c’est finalement rassurant, une jeunesse qui ne se révolte pas ce n’est pas bon pour un pays.
L’autre critère, est le même depuis longtemps, les politiques n’en tiennent pas assez compte, c’est celui de l’éducation que se traduit par le niveau de diplôme. Ce critère distingue fortement l’électorat nationaliste. Il y a une relation décroissante entre le taux de vote FN et le niveau de diplôme et un ratio de 3,3 quand il n’y a pas de différence substantielle pour les autres candidats. Ils sont tous un peu plus représentés chez les plus diplômés. Voilà qui signifie l’idée que c’est l’espérance de progression sociale qui fait en grande partie l’élection, et que celle-ci se construit socialement dans la ressource que représentent les diplômes et les qualifications. Le critère de revenus est moins discriminant, ce qui compte est moins le revenu actuel que celui qu’on espère. Le vote du Front National n’est pas vraiment celui du vote ouvrier, il est celui des non-diplômés. C’est aussi la faiblesse de l’extrême droite : les moins diplômés sont aussi les moins participants au vote.
Avec ces quelques éléments on peut conclure sur deux points. Le premier est un conseil à Macron, s’il veut une belle victoire qu’il fasse un geste aux insoumis, ils ne sont pas sans ressources et sans espoir, ils sont inquiet d’un monde dur où la compétition et l’intolérance se dispute la société. Le second est un second conseil à Emmanuel Macron, Président - comme c’est prévisible sous réserve de rebondissement ce dont les temps actuel semblent généreux, et à son futur gouvernement. Ce n’est pas la rhétorique qui fera refluer le nationaliste et le populisme, ni le fact-checking en dépit du flot d’intox et de mensonge de ce mouvement. Il faudra se décider, s’il l’on est progressiste, à faire que le progrès soit partagé, en particulier en ciblant la jeunesse sans diplôme dont le taux de chômage est de près de 50%. Il n’y a pas une jeunesse il y en a deux, et la figure produite par l’observatoire des inégalités est éloquente.
Chaque jour amène son lot de sondages suscitant plus d’interrogations que de conclusions.
Pour le spécialiste des données c’est un merveilleux bac à sable, surtout quand la foule s’attache à en maintenir l’inventaire comme le fait Wikipédia.
Ce sont les données avec lesquelles nous allons nous amuser après avoir fait un peu de nettoyage et de mise en forme. Quelques jeux avec ces packages rares et précieux qui font de r une planète à explorer, une caverne d’Alibaba, un supermarché magique du nombre.
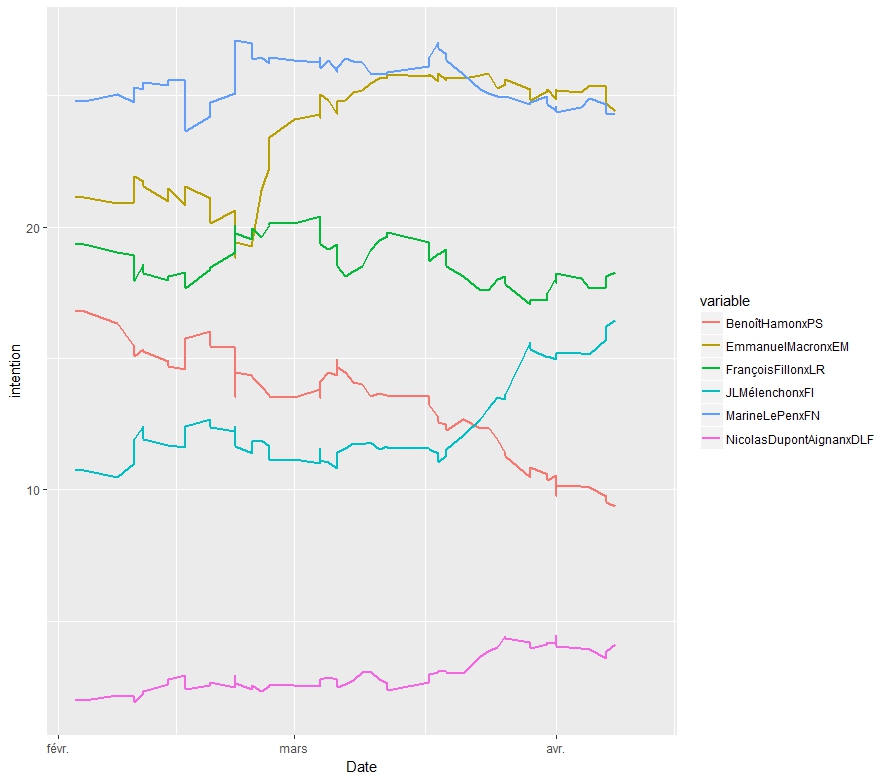
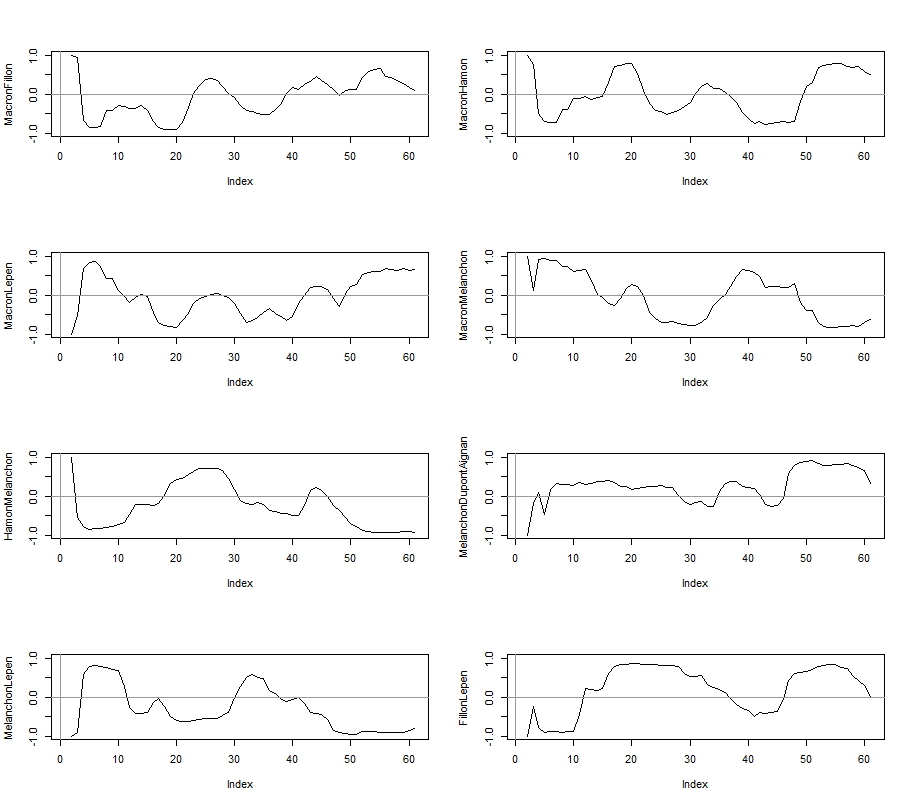
En voici une visualisation pour les 6 principaux adversaires en termes d’intention de vote. Les données sont représentée séquentiellement en fonction du temps. Les aspérités correspondent aux jours où plusieurs sondages ont été publié le même jour. On a lissé les données sur une fenêtre de 3 jours de manière exponentielle (lambda=0,5).
Macron et Le Pen sont aux coudes à coudes, Fillon est largué et semble à peine retrouver de l’air pour respirer, Hamon s’effondre avec une belle détermination, Mélanchon surgit et s’accroche à la roue de vélo de Fillon - allez encore un coup de mollet, l’autre est cuit- , Dupont Aignan s’accroche, avec un peu d’effort il sera peut être remboursé - il pique des coups de bec dans la carcasse c’est de Fillon.
Un premier jeu est naturellement celui du pronostic. Depuis les travaux de 538 les méthodes d’analyses évoluent et se sont ouvertes aux méthodes bayésiennes. Voici en quelques lignes une méthode pour établir un pronostic. Du moins une esquisse de ce qu’on pense être ce qui est utilisé par les spécialistes qui ne donnent pas toujours beaucoup de détails sauf @freakonometrics que signale @bayesreality. Les valeurs initiales sont les moyennes des trois derniers sondages publiés au 11/04/2017.
L’idée principale est que les sondages nous donne moins un résultat qu’une information a priori, lecture est insuffisante pour établir le pronostic. Celui-ci doit prendre en compte la variabilité inhérente aux sondages et fournir une idée plus précise des distributions associées. L’utilisation d’un modèle de distribution de probabilités est indispensable, il servira à générer un grand nombre de variantes possibles à partir de cette première donnée. On simulera 100 000 échantillons pour saisir les configurations les plus inattendues.
Dans le cas d’un premier tour d’élection le bon modèle est celui de Dirichlet. Les résultats du sondage servent de probabilité a priori dans une perspective bayésienne. Pour estimer plus précisément le modèle, on peut inclure aussi compte le nombre de répondant qui détermine la dispersion des probabilités de choix. Dans notre cas nous choissisons un paramètre de 250, pour tenir compte qu’empiriquement les échantillons utilisés sont deux fois moins précis que ce que la théorie pronostique. Avec r ceci se traduit par peu de lignes.
set.seed(789) N <- 100000 probs <- c(.233 , .238, .187, .181, .092, .037 ) # define (extremal) class probabilities#alpha0 = 250 -> pour tenir compte de l’erreur réelle, on divise par 4 l’échantillon moyen utilisé car on l’stime au double des valeurs théorique. alpha0 <- 250 alpha <- alpha0*probs alpha <- matrix( alpha , nrow=N , ncol=length(alpha) , byrow=TRUE ) alpha x <- dirichlet.simul( alpha )
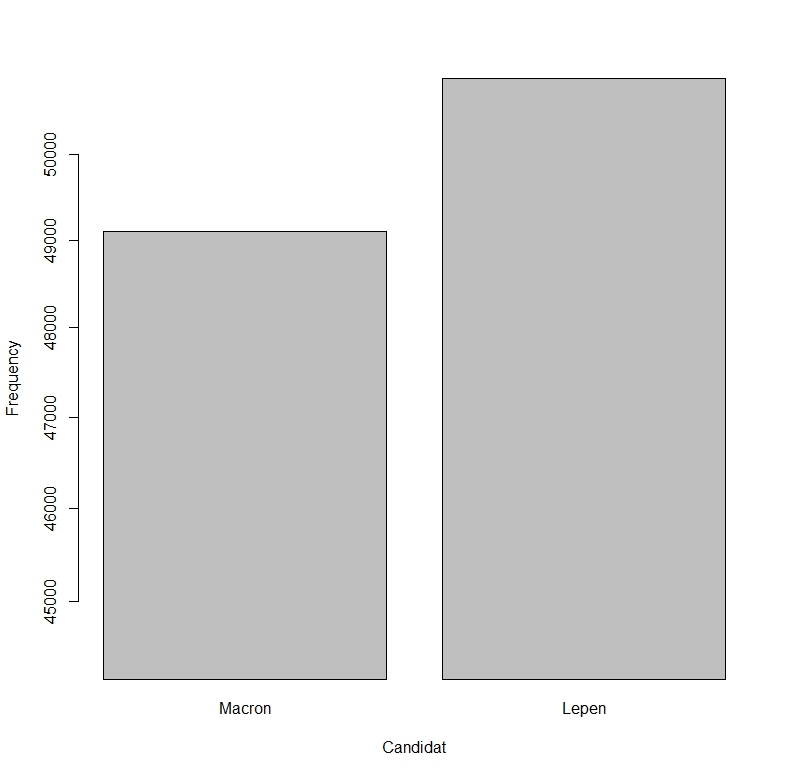
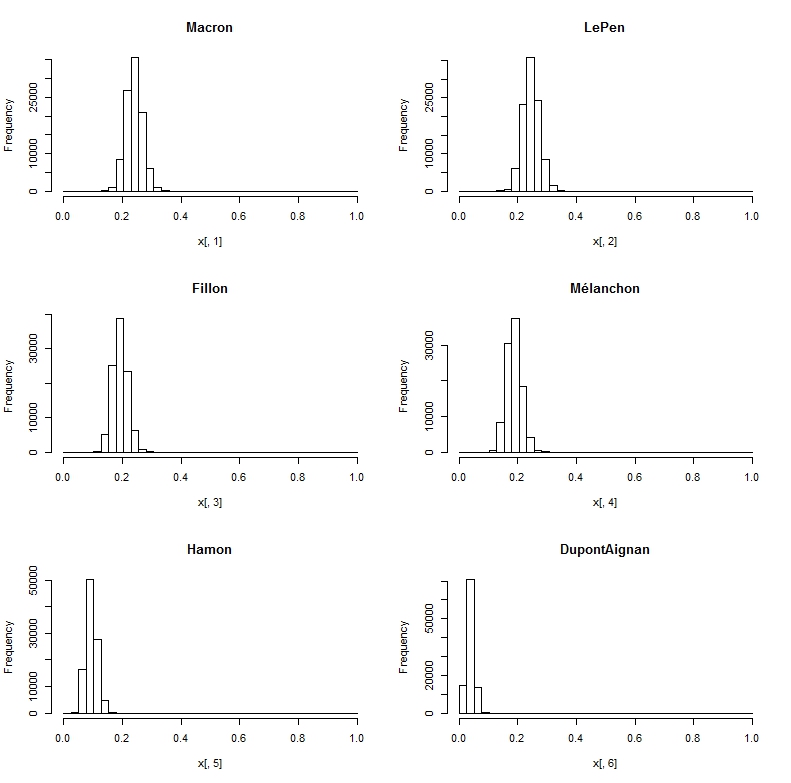
Les résultats sont donnés dans les deux diagrammes suivants. Le premier donne la distribution des probabilités de choix pour chacun des candidats, le second la distribution de probabilité d’arrivée en tête. Seul deux candidats ont une chance, sur la base des trois derniers sondages, Marine Le Pen a une toute petite avance sur Macron.
Simulation : nombre de 1ère position ( n=100 000)
distributionProbCandidats
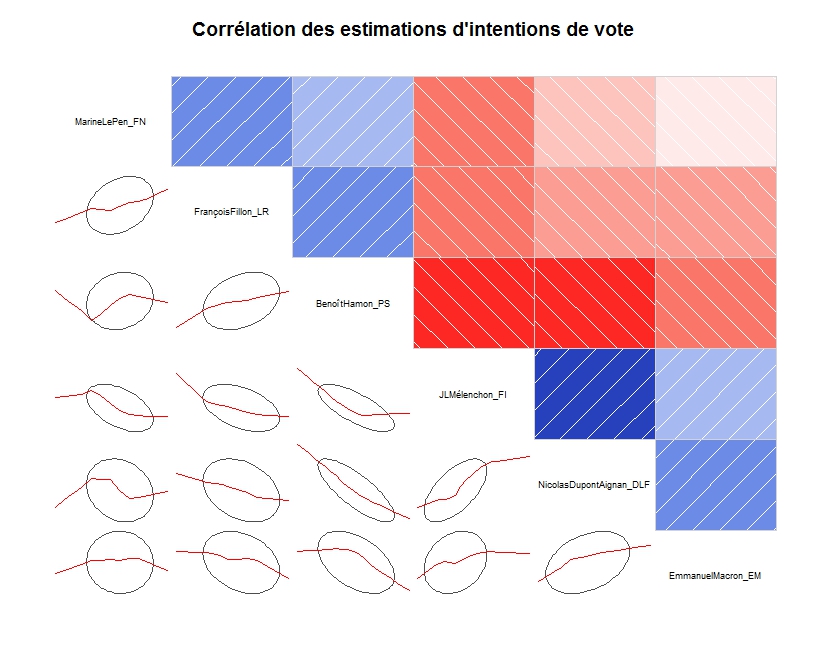
Naturellement ce qui interroge d’abord c’est la dynamique des hésitations et le jeu des reports. Qui prend à qui? L’analyse des corrélations peut nous donner une première idée. On y notera la nette corrélation négative entre les intentions de vote pour Hamon et Mélanchon - la piscine se vide- , tout autant qu’un lien positif entre celle pour Mélanchon et de manière surprenante pour Dupont-Aignan? Est-ce l’axe souverainiste? Pour Macron le point intéressant est qu’il est peu lié aux autres, il n’attire pas de camp particulier - sauf celui des modernes de tout les camps! à l’exception de Hamon - la piscine se déverse dans un second bassin. Fillon et Le Pen se déchirent ce qui reste de l’électorat de droite.
Corrélations Glissantes
Corrélationsdes intentions,
Matrice des corrélations
L’analyse de ces corrélations doit être prudente car elle suppose qu’elles restent stables dans le temps.
L’étude de cette dynamique va nous fournir un troisième jeu. A cette fin on utilise le package Roll de r et sa fonction roll_corr. Il s’agit de calculer une corrélation glissante en fonction du temps, selon une fenêtre d’observations ( ici 16 j) et une pondération exponentielle (0,9). 8 des 15 couples figurent dans la diapo 3.
Ces corrélations sont intéressantes, mais se lisent difficilement. Un premier résultat est la forte fluctuation des corrélation qui passent du positif au négatif, seraient-elles ératiques? Le cas Hamon Melanchon est le plus clair, la corrélation devient de plus en plus négative, indiquant le sens de la conversion : Mélanchon monte de plus en plus parce que Hamon lui fournit ses bataillons. DAns tout les cas il n’y a pas de stabilité dans le temps, les rapports de forces varient, passe d’un pivot à l’autre.
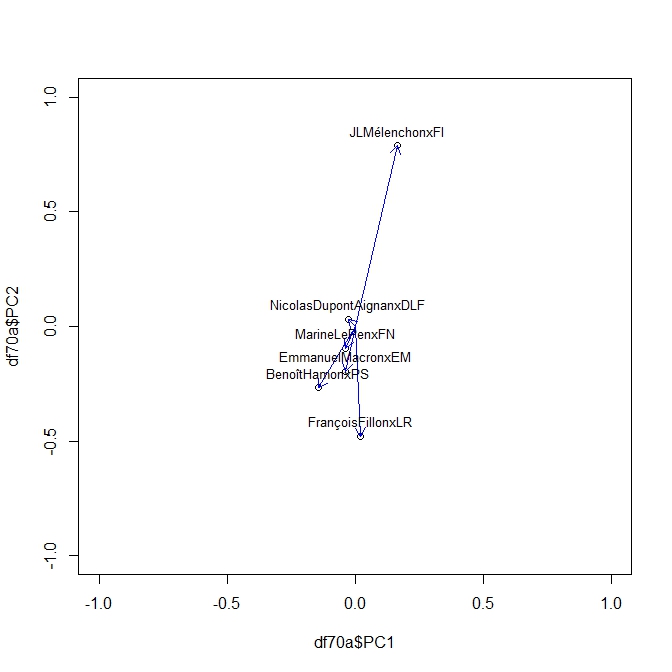
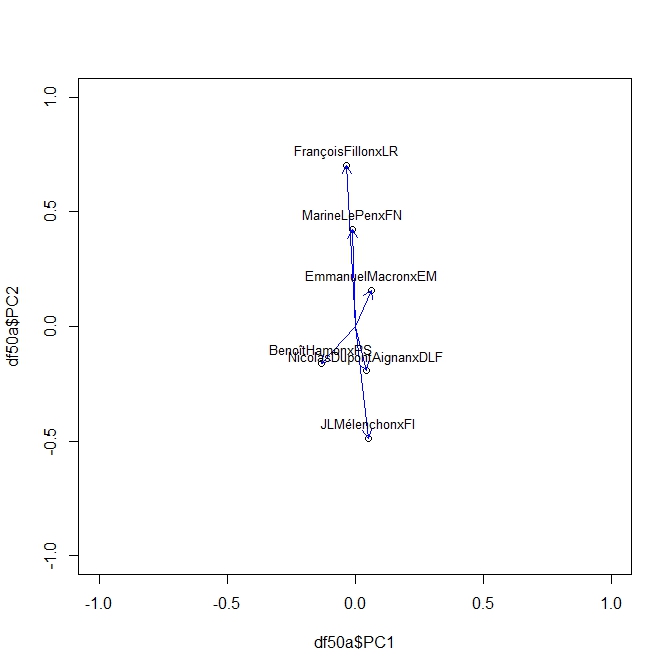
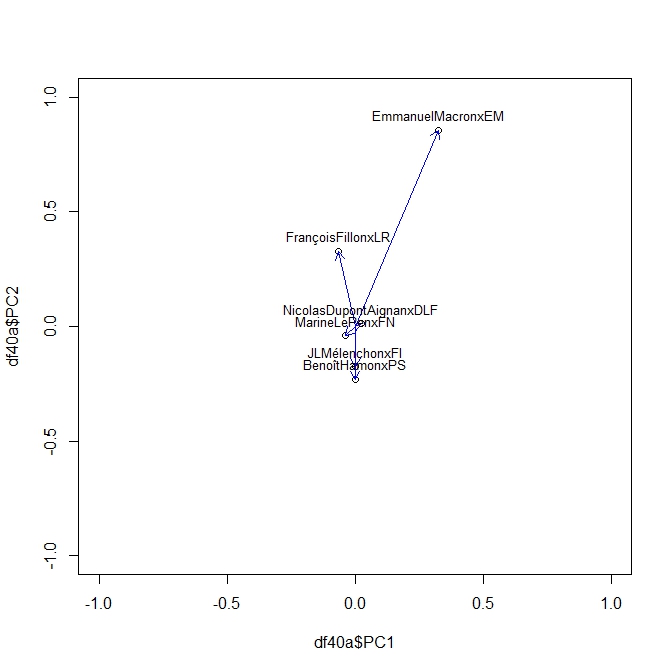
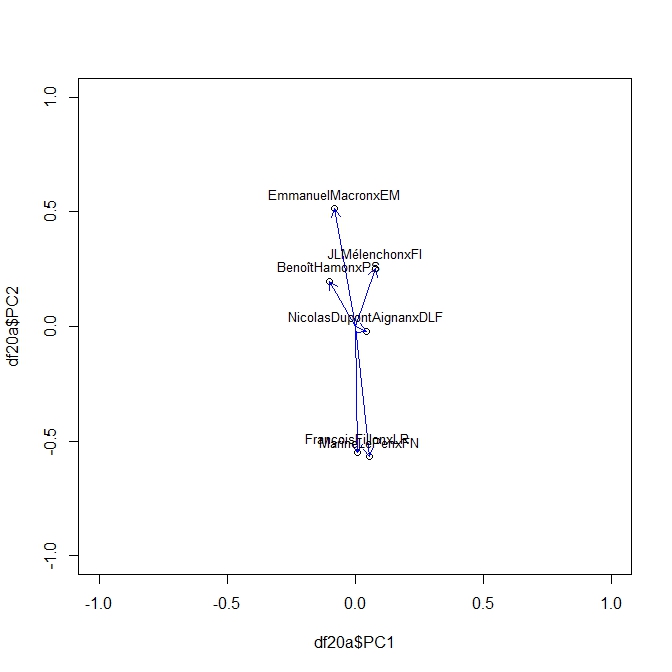
Puisqu’il s’agit d’une matrice de corrélation on peut l’analyser avec une ACP toute aussi glissante que nos corrélations, c’est une ACP dynamique. Le même Package Roll nous fournit la solution avec une fonction très simple Rool_eigen
On produit ainsi une série d’Acp pour chaque élément de la séquence des sondages. En voici ci dessous des exemples à t=20,40, 50,70. On peut y lire les moment de la campagne. Pour son moment le plus récent on voit clairement l’attraction de Mélanchon s’exercer sur toute les factions. Le début de campagne était plus classique dans une opposition des forces de droite et de gauche.
PCA70
PCA50
PCA40
PCA20
Il y a encore beaucoup de jeux possibles. Et nos codes sont faits à l’arrache. Une chose est sure, la statistique gagne avec ces élections, jamais on a autant calculé, et jamais on a été autant surpris. C’est que les structures de vote deviennent plus subtiles, et demandent des méthodes plus fines, plus riches, plus interprétative.
Nous n’avons pas été au bout de l’excercice, nous n’avons pas combiné les deux tours. Nous n’avons pas exploré toutes les régularisations possibles de nos modèles. Nous voulions juste inviter le lecteur à explorer les nouvelles ressources des DataSciences pour comprendre plus que pour prévoir les ressorts d’une élection à la présidence.
PS: et si quelqu’un a envie de faire du code propre, le mien est crasseux. Le tableau de donnée et le script r sont à disposition. Just mail me.




 Il y a des moments de bonheur. Par exemple, celui où on découvre un jeu de données merveilleux et que l’on part à son exploration. Ce jeu de donnée est celui de l’
Il y a des moments de bonheur. Par exemple, celui où on découvre un jeu de données merveilleux et que l’on part à son exploration. Ce jeu de donnée est celui de l’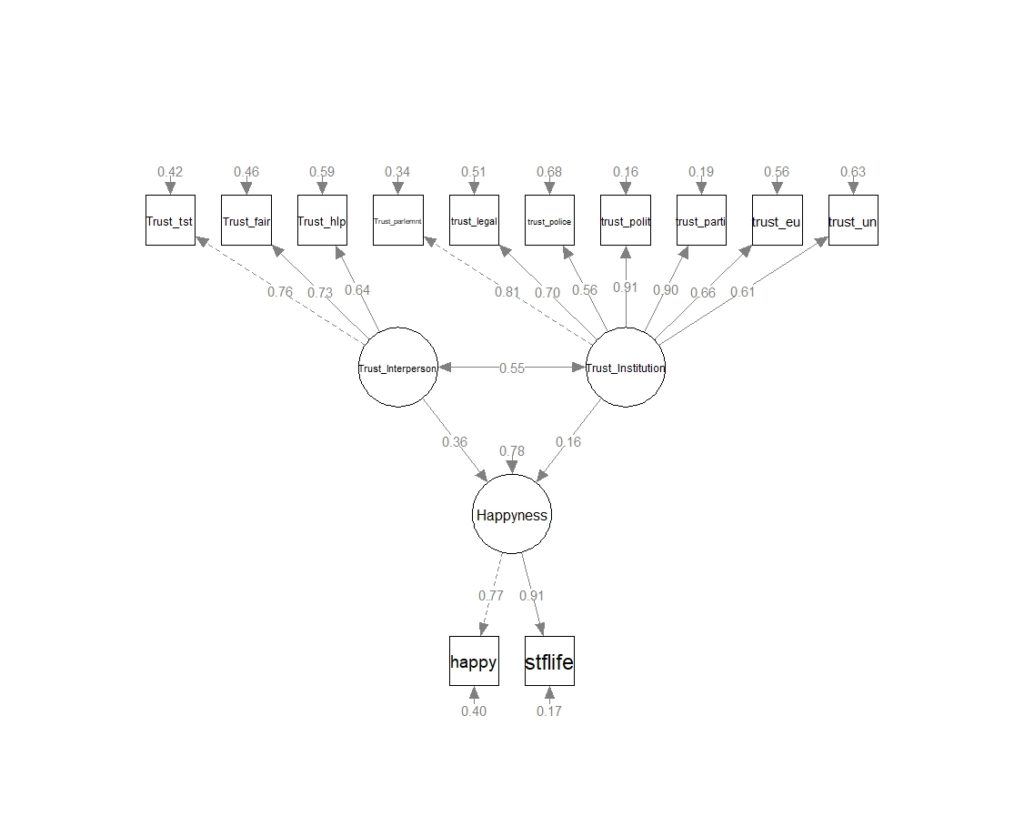 Avoir autant de données pour une presque trivialité peut sembler inutile, sauf si l’on cherche à voir ce qui peut faire varier ce modèle. L’idée est donc simplement d’évaluer ce modèle pour différents groupes. La seule chose à faire est de modifier l’ajustement avec cette ligne :
Avoir autant de données pour une presque trivialité peut sembler inutile, sauf si l’on cherche à voir ce qui peut faire varier ce modèle. L’idée est donc simplement d’évaluer ce modèle pour différents groupes. La seule chose à faire est de modifier l’ajustement avec cette ligne :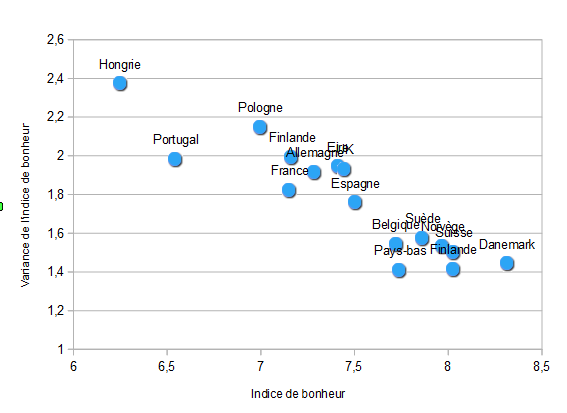
 Le propre des êtres autonomes est leur capacité à identifier des signaux et à y répondre de manière adéquate.
Le propre des êtres autonomes est leur capacité à identifier des signaux et à y répondre de manière adéquate.