Une situation courante dans les entreprises de services et de distribution est de mesurer la satisfaction ou d’autres indicateurs proches, pour des unités géographiques distinctes et identifiables : des points de ventes, des bureaux d’orientation, des bornes ou automates, une multitude de localisation. Quand le réseau comprend des centaines d’unités, certaines variétés, certaines d’analyse sont utiles.
C’est l’objet de cette étude, une première plongée dans une jolie base. 300 000 jugements de satisfaction.
Ce n’est pas tout à fait du big data mais cela donne une idée des méthodes de résolution qui doivent être mises en œuvre quand les données sont abondantes. Elles ne sont pas forcément complexes, elles tirent l’avantage d’une répétition. Pour chaque unité nous pouvons ajuster un modèle, une variation. Et comparer.
Dans notre cas il s’agit de données relatives à une mesure de satisfaction qui concerne 166 points de ventes d’une chaine de distribution dans un pays européen. Et juste une première analyse pour tester des données. Pour chacun des points de vente les tailles d’échantillons sont de l’ordre de 1000. la médiane est vers 900. Nous disposons sur cette base de données de près de 170 000 observations, pour 166 unités d’analyse - des points de ventes. Nous pouvons donc pour chacune d’elles estimer un modèle de satisfaction dont la structure est :
Sij=aij+a1jOffre(ij)+a2jMerch(ij)+a3jCommodité(ij)+a4j*Personnel(ij)+eij
( i indice l’individu et j le point de vente)
Les paramètres correspondent ici à l’accroissement de satisfaction globale assurée par le fait d’être noté parmi les 15% meilleurs. Si le coefficient obtenu est de 0,5, cela signifie qu’être noté parmi les 15% des meilleurs accroit la satisfaction globale de 0,5 point. Voilà qui peut servir de point d’ancrage pour évaluer les valeurs de l’étude.
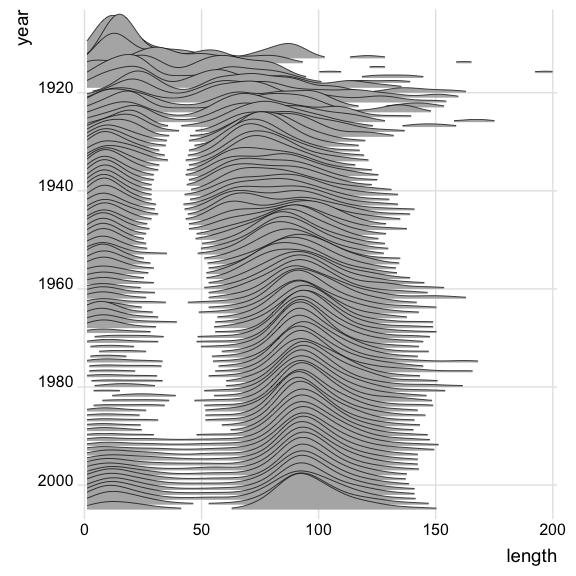
L’idée est dans l’esprit de la méta-analyse de prendre partie de la possibilité de faire une étude des études et ainsi de mieux comprendre et d’ajuster les modèles. Un exemple simple est donnée dans l’illustration suivante où un modèle de satisfaction multi-attributs est estimé à chaque point de vente. On peut ainsi étudier directement les distribution des paramètres, et d’essayer de comprendre en fonction de quoi elles varient.
Dans notre cas il s’agit de 4 facteurs principaux : l’assortiment des produit, la qualité du merchandising, la facilité de circulation dans le point de vente et la qualité des interventions du personnel. On observe que ces effets varient du simple au double. Dans le cas du merchandising qui a la valeur moyenne la élevée pour sa contribution (de l’ordre de 0.67), la plage de valeur va de près de 0.5 jusqu’à presque 1. L’influence de cette variable change fortement d’un point à l’autre. Il reste à savoir pourquoi.
Ces sensibilités ne sont pas tout à fait indépendantes comme en témoigne le tableau des corrélations suivant. Il y a un lien significatif entre l’offre et le merchandising, une autre entre la qualité du personnel et la facilitation de circulation. Dans certain cas c’est la manière dont l’offre est présentée qui compte, dans d’autres c’est l’orientation dans le magasin qui est déterminante. Les corrélations partielles confortent la force de ces liens.
On sera étonné que seul la sensibilité du merchandising varie négativement avec la taille des magasins, plus ils comprennent de personnel et moins la mise en scène est importante elle reste l’apanage des petits formats.C’est ici qu’il faut mettre en scène les produits et motiver les gérants.
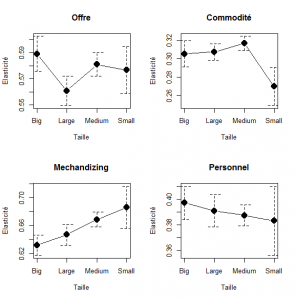
Ces coefficients de sensibilité semblent cependant peu varier avec des variables telles que la taille du magasin, la localisation, ou même la région. En voici un résumé pour la taille des points de ventes.
A cette échelle peu de différences sont significatives, mais des patterns apparaissent. On comprend mieux cet effet dans la figure suivante ou les niveaux des facteurs varient avec la taille : la mise en place est d’autant plus importante que les magasins sont petits.
A l’inverse même si ce n’est pas tout à fait décisif, dans les grandes unités le personnel a un poids plus fort sur la formation de la satisfaction. Mais ce n’est qu’un facteur.
Donnons aussi les différences selon la localisation : en centre ville ou à l’extérieur. Très clairement le merchandising est plus important dans les unités hors centre. Dans cet environnement c’est sur la mise en place des produit qu’on peut obtenir une meilleure évaluation. Les données sont cohérentes. A contrario dans les zones urbaines, où les unités sont grandes c’est le personnel qui est la clé. On le comprend bien, le confort des visites devient important quand l’offre ne peut plus être bien évaluée, l’abondance demande de l’aide et des efforts.
Un des enseignements de cette étude est que les paramètres de sensibilité des attributs de la satisfaction varient fortement selon les points de ventes. Ces variations sont peu expliquées par la taille, la région, ou l’effectif. D’autres facteurs déterminent sans doute ces variations, il reste à les découvrir. L’essentiel d’en prendre compte : une politique bonne dans un magasin n’est peut-être pas la meilleure dans un autre.
Mais la méthode simple rend bien compte de cet enjeu : même si nous pouvons user de modèles sophistiqués et subtils comme les modèles multiniveaux (1), c’est l’ingéniosité qui doit avoir le premier mot, un ingéniosité qui rende compte que les modèles varient dans leurs paramètres, Rares sont les travaux de cet ordre, une exception est le travail de Mittal et kamakura(2)
Il reste à mettre en œuvre les procédures et les cadres théoriques qui en exploiteront la moelle : ces variations d’un lieu à l’autre. Cette idée que les modèles n’ont de sens que dans la variation de leurs paramètres. Et que c’est celà qui permet une gestion fine des canaux, de comparer les unité et d’évaluer au mieux l’allocation des ressources.