Chaque jour amène son lot de sondages suscitant plus d’interrogations que de conclusions.
Chaque jour amène son lot de sondages suscitant plus d’interrogations que de conclusions.
Pour le spécialiste des données c’est un merveilleux bac à sable, surtout quand la foule s’attache à en maintenir l’inventaire comme le fait Wikipédia.
Ce sont les données avec lesquelles nous allons nous amuser après avoir fait un peu de nettoyage et de mise en forme. Quelques jeux avec ces packages rares et précieux qui font de r une planète à explorer, une caverne d’Alibaba, un supermarché magique du nombre.
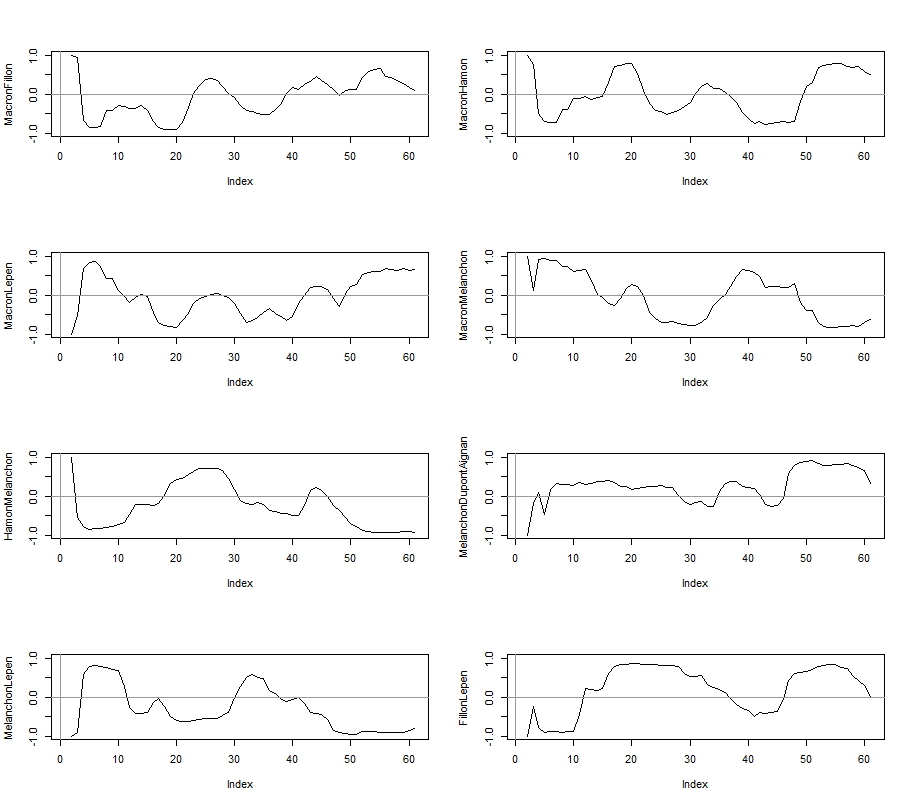
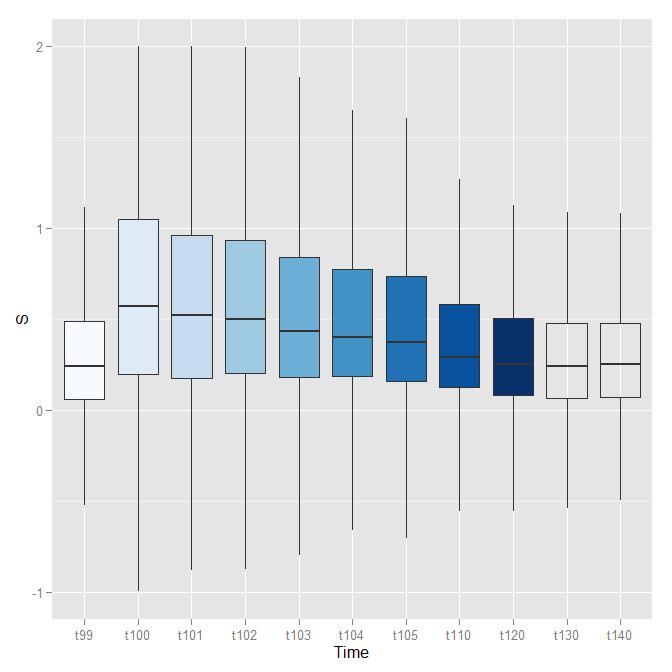
En voici une visualisation pour les 6 principaux adversaires en termes d’intention de vote. Les données sont représentée séquentiellement en fonction du temps. Les aspérités correspondent aux jours où plusieurs sondages ont été publié le même jour. On a lissé les données sur une fenêtre de 3 jours de manière exponentielle (lambda=0,5).
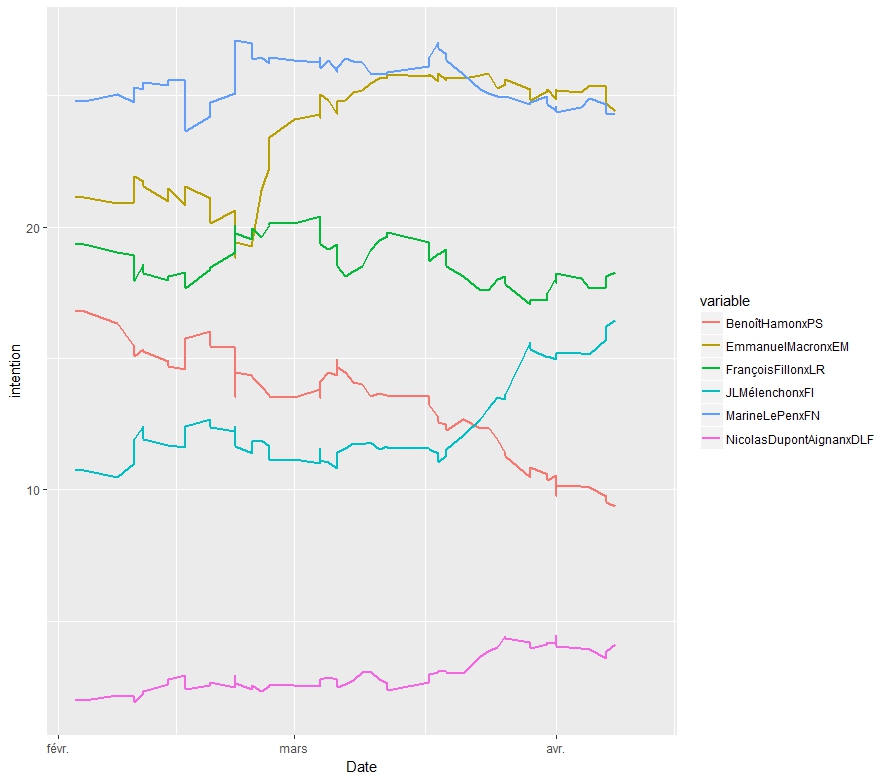
Macron et Le Pen sont aux coudes à coudes, Fillon est largué et semble à peine retrouver de l’air pour respirer, Hamon s’effondre avec une belle détermination, Mélanchon surgit et s’accroche à la roue de vélo de Fillon - allez encore un coup de mollet, l’autre est cuit- , Dupont Aignan s’accroche, avec un peu d’effort il sera peut être remboursé - il pique des coups de bec dans la carcasse c’est de Fillon.
Un premier jeu est naturellement celui du pronostic. Depuis les travaux de 538 les méthodes d’analyses évoluent et se sont ouvertes aux méthodes bayésiennes. Voici en quelques lignes une méthode pour établir un pronostic. Du moins une esquisse de ce qu’on pense être ce qui est utilisé par les spécialistes qui ne donnent pas toujours beaucoup de détails sauf @freakonometrics que signale @bayesreality. Les valeurs initiales sont les moyennes des trois derniers sondages publiés au 11/04/2017.
L’idée principale est que les sondages nous donne moins un résultat qu’une information a priori, lecture est insuffisante pour établir le pronostic. Celui-ci doit prendre en compte la variabilité inhérente aux sondages et fournir une idée plus précise des distributions associées. L’utilisation d’un modèle de distribution de probabilités est indispensable, il servira à générer un grand nombre de variantes possibles à partir de cette première donnée. On simulera 100 000 échantillons pour saisir les configurations les plus inattendues.
Dans le cas d’un premier tour d’élection le bon modèle est celui de Dirichlet. Les résultats du sondage servent de probabilité a priori dans une perspective bayésienne. Pour estimer plus précisément le modèle, on peut inclure aussi compte le nombre de répondant qui détermine la dispersion des probabilités de choix. Dans notre cas nous choissisons un paramètre de 250, pour tenir compte qu’empiriquement les échantillons utilisés sont deux fois moins précis que ce que la théorie pronostique. Avec r ceci se traduit par peu de lignes.
set.seed(789)
N <- 100000
probs <- c(.233 , .238, .187, .181, .092, .037 ) # define (extremal) class probabilities#alpha0 = 250 -> pour tenir compte de l’erreur réelle, on divise par 4 l’échantillon moyen utilisé car on l’stime au double des valeurs théorique.
alpha0 <- 250
alpha <- alpha0*probs
alpha <- matrix( alpha , nrow=N , ncol=length(alpha) , byrow=TRUE )
alpha
x <- dirichlet.simul( alpha )
Les résultats sont donnés dans les deux diagrammes suivants. Le premier donne la distribution des probabilités de choix pour chacun des candidats, le second la distribution de probabilité d’arrivée en tête. Seul deux candidats ont une chance, sur la base des trois derniers sondages, Marine Le Pen a une toute petite avance sur Macron.
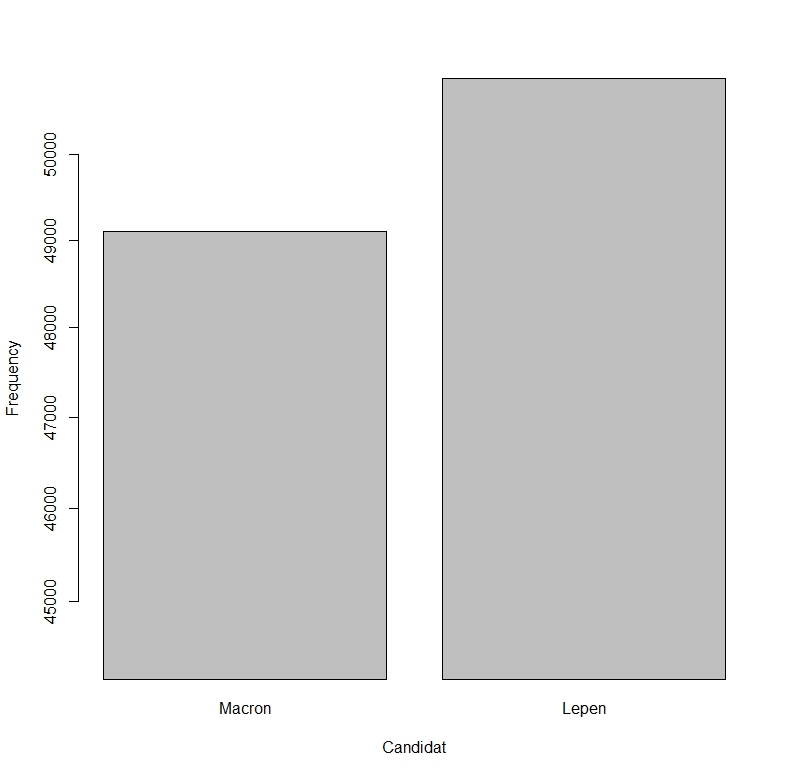
Simulation : nombre de 1ère position ( n=100 000)
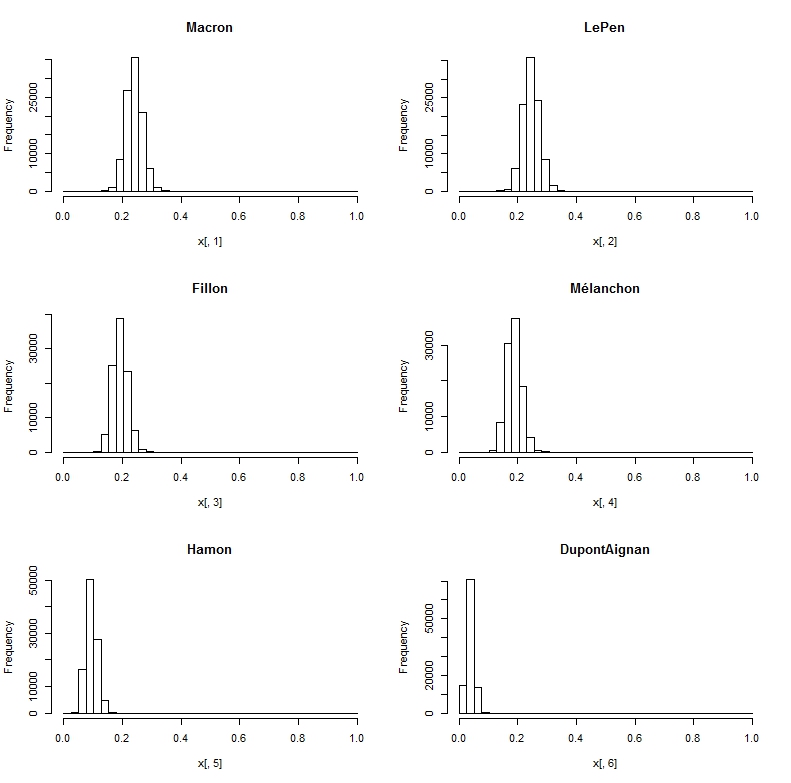
distributionProbCandidats
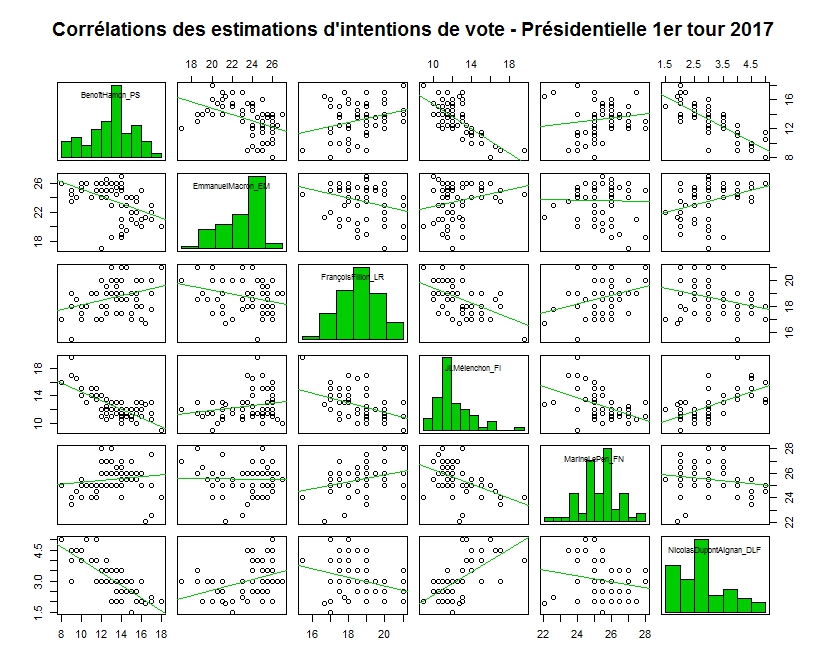
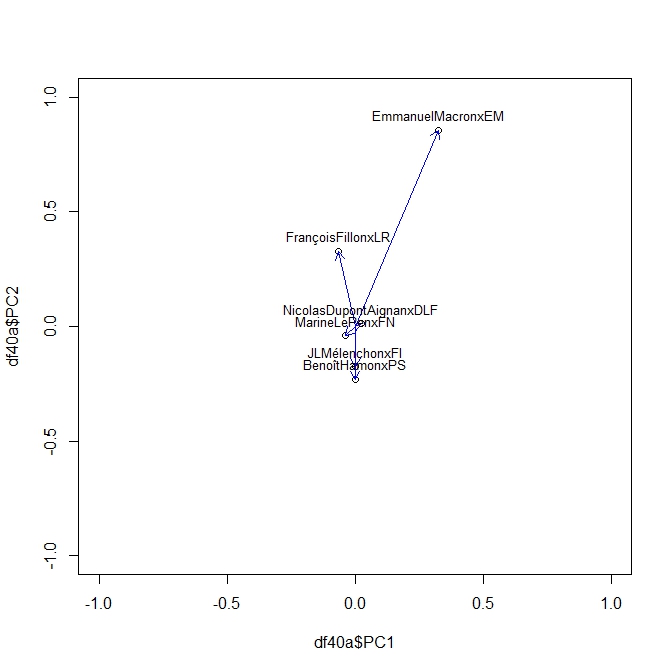
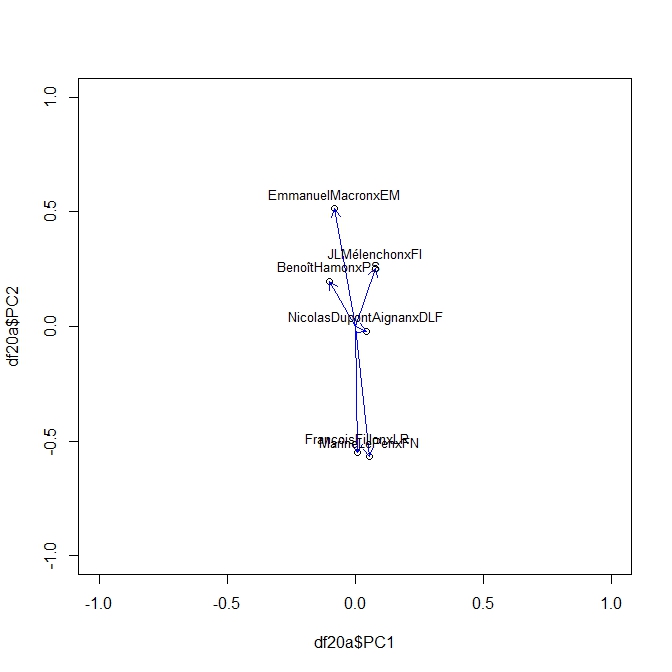
Naturellement ce qui interroge d’abord c’est la dynamique des hésitations et le jeu des reports. Qui prend à qui? L’analyse des corrélations peut nous donner une première idée. On y notera la nette corrélation négative entre les intentions de vote pour Hamon et Mélanchon - la piscine se vide- , tout autant qu’un lien positif entre celle pour Mélanchon et de manière surprenante pour Dupont-Aignan? Est-ce l’axe souverainiste? Pour Macron le point intéressant est qu’il est peu lié aux autres, il n’attire pas de camp particulier - sauf celui des modernes de tout les camps! à l’exception de Hamon - la piscine se déverse dans un second bassin. Fillon et Le Pen se déchirent ce qui reste de l’électorat de droite.
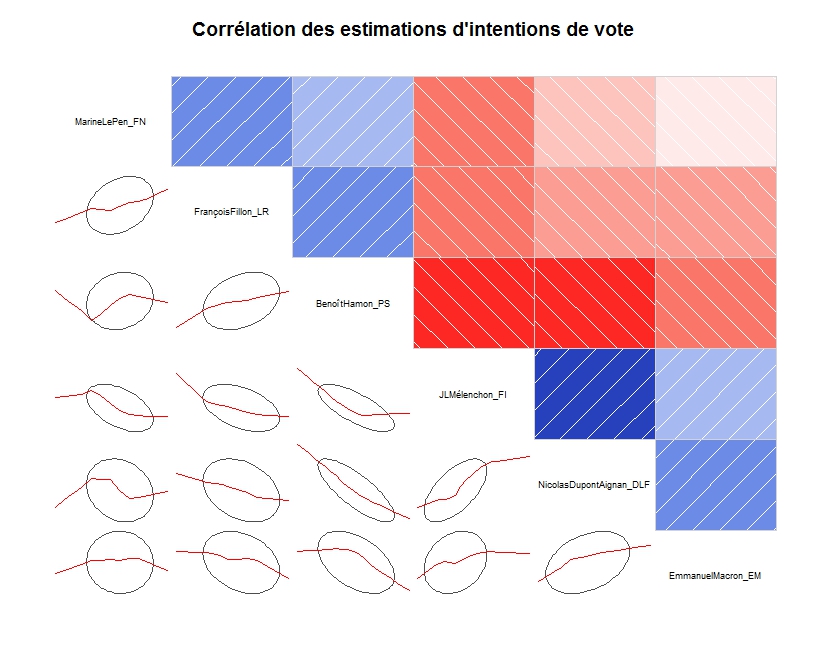
Corrélationsdes intentions,
L’analyse de ces corrélations doit être prudente car elle suppose qu’elles restent stables dans le temps.
L’étude de cette dynamique va nous fournir un troisième jeu. A cette fin on utilise le package Roll de r et sa fonction roll_corr. Il s’agit de calculer une corrélation glissante en fonction du temps, selon une fenêtre d’observations ( ici 16 j) et une pondération exponentielle (0,9). 8 des 15 couples figurent dans la diapo 3.
Ces corrélations sont intéressantes, mais se lisent difficilement. Un premier résultat est la forte fluctuation des corrélation qui passent du positif au négatif, seraient-elles ératiques? Le cas Hamon Melanchon est le plus clair, la corrélation devient de plus en plus négative, indiquant le sens de la conversion : Mélanchon monte de plus en plus parce que Hamon lui fournit ses bataillons. DAns tout les cas il n’y a pas de stabilité dans le temps, les rapports de forces varient, passe d’un pivot à l’autre.
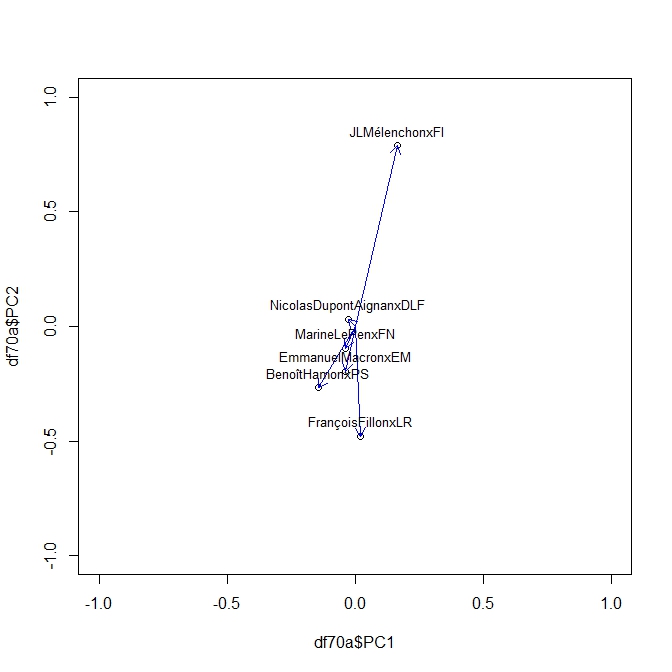
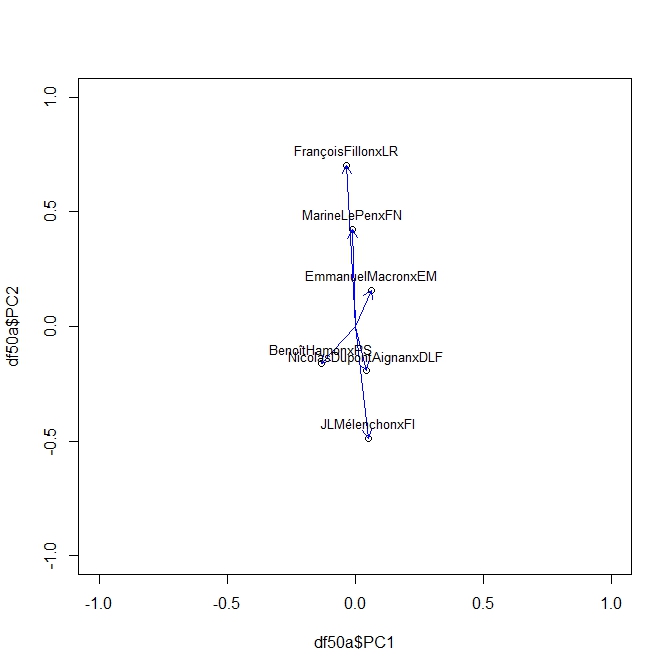
Puisqu’il s’agit d’une matrice de corrélation on peut l’analyser avec une ACP toute aussi glissante que nos corrélations, c’est une ACP dynamique. Le même Package Roll nous fournit la solution avec une fonction très simple Rool_eigen
—-
Corollb<-roll_eigen(Coroll, 20, min_obs = 1)
—-
On produit ainsi une série d’Acp pour chaque élément de la séquence des sondages. En voici ci dessous des exemples à t=20,40, 50,70. On peut y lire les moment de la campagne. Pour son moment le plus récent on voit clairement l’attraction de Mélanchon s’exercer sur toute les factions. Le début de campagne était plus classique dans une opposition des forces de droite et de gauche.
Il y a encore beaucoup de jeux possibles. Et nos codes sont faits à l’arrache. Une chose est sure, la statistique gagne avec ces élections, jamais on a autant calculé, et jamais on a été autant surpris. C’est que les structures de vote deviennent plus subtiles, et demandent des méthodes plus fines, plus riches, plus interprétative.
Nous n’avons pas été au bout de l’excercice, nous n’avons pas combiné les deux tours. Nous n’avons pas exploré toutes les régularisations possibles de nos modèles. Nous voulions juste inviter le lecteur à explorer les nouvelles ressources des DataSciences pour comprendre plus que pour prévoir les ressorts d’une élection à la présidence.
PS: et si quelqu’un a envie de faire du code propre, le mien est crasseux. Le tableau de donnée et le script r sont à disposition. Just mail me.

 Objectif : rédiger une note de deux pages présentant une méthode d’analyse en marketing et utilisant des ressources r. Elle sera, si très satisfaisante, ajoutée à tex2r.
Objectif : rédiger une note de deux pages présentant une méthode d’analyse en marketing et utilisant des ressources r. Elle sera, si très satisfaisante, ajoutée à tex2r.