L’analyse conjointe est sans doute la méthode la plus spécifique du marketing, même s’il semble qu’elle soit un peu négligée de nos jours alors même que l’environnement digital en permettrait un renouveau. Dans cette note nous nous contenterons de présenter pas à pas, son application via le package Conjoint sur r , développé par Andrzej Bak et Tomasz Bartlomowicz.
L’analyse conjointe est sans doute la méthode la plus spécifique du marketing, même s’il semble qu’elle soit un peu négligée de nos jours alors même que l’environnement digital en permettrait un renouveau. Dans cette note nous nous contenterons de présenter pas à pas, son application via le package Conjoint sur r , développé par Andrzej Bak et Tomasz Bartlomowicz.
Pour plus de détails sur la méthode elle-même on jettera un coup d’oeil en fin de post à une bien vieille note écrite avec Jean-claude Liquet, imparfaite mais utile au moins pour les étudiants. Pour un état de l’art récent on ira voir ce texte , pour des applications professionnelles on ira voir le site de Sawtooth.
L’exemple que nous utilisons est un jeu de donnée crée par une des étudiante du Master MOI, dans le but de tester le rôle de certain signes de qualité dans le choix d’un vin. La première étape de l’analyse conjointe consiste à choisir des attributs que l’on pense déterminant et à définir leur modalités. La seconde étape vise à générer des concepts à partir de ces attributs. Comme le nombre de combinaison devient rapidement important, on utilise généralement des méthodes de plan d’expérience incomplets ( toutes les combinaisons ne sont pas testées, et orthogonaux ( on s’arrange pour que les modalités apparaissent de manière équilibrée et non corrélées entres elle).
La procédure ici est très simple : on appele le package “conjoint”, pis on créé le fichier vin qui va contenir les différents concept en définition les attributs ( variables : type, pays…) et leurs modalités (“doux, “demi-sec”,…). Le plan factoriel est défini par la commande caFactorialDesign avec ici deux options : le choix de l’option ” fractional”, et une limite dans le nombre de concept que l’on a fixé à 13.
library (conjoint)
library (Rcmdr)
Vin<-expand.grid(
Type<-c(“Doux”,”demi-sec”,”sec”),
Pays<-c(“Bourgogne”,”Bordeaux”,”Italie-Nord”,”Afrique du Sud”),
Marque<-c(“Millessima”,”1jour1vin”,”Nicolas”),
Prix<-c(“7€”,”12€”,”20€”),
Label<-c(“Médaille d’or “,”NC”),
Environ<-c(“Bio”,”NC”),
Annee<-c(“2014”, “2011”))design_vin<-caFactorialDesign(data=Vin,type=”fractional”,cards=13)
Le résultat est obtenu avec
print(design_vin)
le voici :
Var1 Var2 Var3 Var4 Var5 Var6 Var7
49 Doux Bourgogne 1jour1vin 12€ Médaille d'or Bio 2014
81 sec Italie-Nord Millessima 20€ Médaille d'or Bio 2014
95 demi-sec Afrique du Sud 1jour1vin 20€ Médaille d'or Bio 2014
176 demi-sec Italie-Nord Nicolas 12€ NC Bio 2014
208 Doux Bordeaux Nicolas 20€ NC Bio 2014
221 demi-sec Bordeaux Millessima 7€ Médaille d'or NC 2014
360 sec Afrique du Sud Nicolas 7€ NC NC 2014
458 demi-sec Bourgogne Nicolas 7€ Médaille d'or Bio 2011
558 sec Bordeaux 1jour1vin 7€ NC Bio 2011
586 Doux Afrique du Sud Millessima 12€ NC Bio 2011
667 Doux Italie-Nord 1jour1vin 7€ Médaille d'or NC 2011
714 sec Bordeaux Nicolas 12€ Médaille d'or NC 2011
842 demi-sec Bourgogne 1jour1vin 20€ NC NC 2011
|
Parmi les 3x4x2x3x2x2=288 concept possibles seuls 13 ont été choisis. Est-ce trop peu? Un moyen de tester celà est de calculer les corrélations entre les modalités. C’est une fonction offerte par le package :
design_vin2<-caEncodedDesign(design_vin)
print(cor(design_vin2))
En voici le résultat, et c’est entre la var 7 et 4 qu’on encourage la corrélation la plus forte. Dans la pratique on fait différent essais pour trouver le meilleur compromis. Dans notre exemple on se satisfera de cette solution.
Var1 Var2 Var3 Var4 Var5 Var6
Var1 1.0000000 0.15304713 0.10586263 -0.10586263 0.17593289 -0.17593289
Var2 0.1530471 1.00000000 -0.11216750 0.11216750 0.17605477 0.04142465
Var3 0.1058626 -0.11216750 1.00000000 0.23275862 0.08596024 0.08596024
Var4 -0.1058626 0.11216750 0.23275862 1.00000000 -0.08596024 -0.08596024
Var5 0.1759329 0.17605477 0.08596024 -0.08596024 1.00000000 0.07142857
Var6 -0.1759329 0.04142465 0.08596024 -0.08596024 0.07142857 1.00000000
Var7 0.1759329 -0.04142465 -0.08596024 -0.28653413 0.23809524 -0.07142857
La troisième étape est celle de la collecte d’information. On essaiera de donner plus de réalisme en proposant les concepts sous formes d’image (celle qui illustre le post en est un exemple) ou encore mieux sous la forme de maquette. Quant au nombre de sujet, une remarque importante est qu’il n’a pas de limite inférieure pour la raison simple que le modèle est calculé individu par individu : ce que l’on cherche c’est naturellement à prédire le classement des concepts à partir des profils, et cela individu par individu. Naturellement les conditions d’échantillonnage habituelles interviennent si l’on veut généraliser à une population, si l’on veut segmenter ou faire des comparaisons entre des groupes d’individus particulier. Dans notre exemple on se contente de 36 individus, c’est largement insuffisant pour généraliser, mais bien assez pour les vertus de l’exemple.
Le fichier de données recueillis par notre étudiante apparait sous la forme suivante : C1, C2,… représente le premier puis le second choix etc. Nous allons devoir le remettre en ordre pour qu’il puisse être traité.
ID SEXE C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13
1 1 homme 52 458 584 105 627 654 311 775 514 120 424 253 828
2 2 femme 105 775 52 458 828 654 253 311 627 120 584 514 424
3 3 homme 52 514 105 627 253 654 120 311 458 584 424 828 775
4 4 homme 52 584 105 627 775 654 120 311 458 514 424 253 828
….
L’ordre requis par le package est un fichier “long” qui énumère les individus, les concepts dans leur ordre de production, et le classement de ces concepts. Une petite manipulation doit être donc excecutée avec une fonction très utile de r : la fonction ” reshape” :
MemoireVin_rank3 <- reshape(MemoireVin_rank2, varying=list(c(“C1″,”C2″,”C3″,”C4″,”C5″,”C6″,”C7″
,”C8″,”C9″,”C10″,”C11″,”C12″,”C13”)), idvar = “ID”, v.names=”concept”,direction = “long”)
On trie le fichier ensuite avec
MemoireVin_rank4<-MemoireVin_rank3[order(MemoireVin_rank3[,4],decreasing=F),]
MemoireVin_rank4<-MemoireVin_rank4[order(MemoireVin_rank4[,1],decreasing=F),]
et l’on crée un fichier de label pour l’esthétique:
l’analyse conjointe proprement dite peut être exécutée avec la simple commande :
Conjoint(MemoireVin_rank4$concept,design_vin2,label)
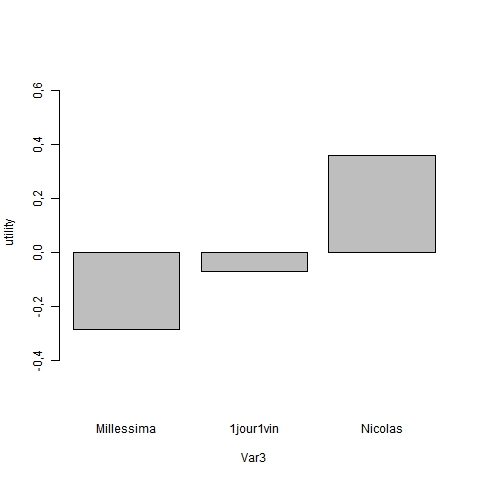
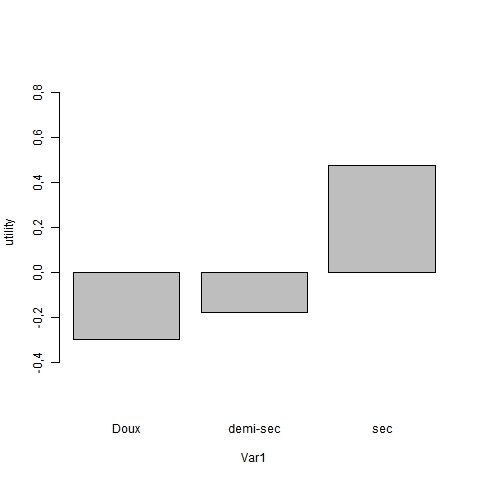
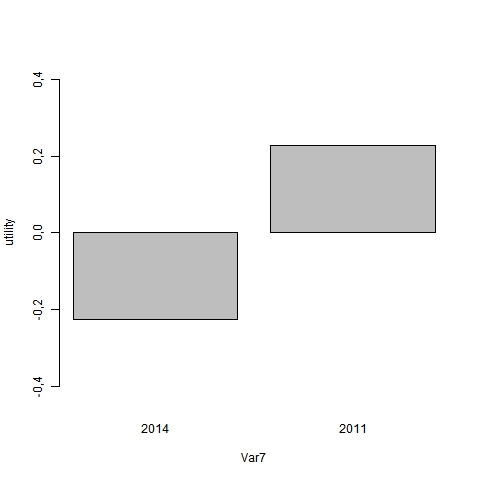
qui produit les résultats principaux suivants: c’est à dire les utilités partielles ( path-worth) et le poids des attributs (on omet le modèle de régression et les tests associés qui sont redondants)
Residual standard error: 3,448 on 442 degrees of freedom
Multiple R-squared: 0,175, Adjusted R-squared: 0,1526
F-statistic: 7,811 on 12 and 442 DF, p-value: 2,991e-13
[1] “Part worths (utilities) of levels (model parameters for whole sample):”
levnms utls
1 intercept 7,3099
2 Doux 0,1999
3 demi-sec 0,8055
4 sec -1,0054
5 Bourgogne -0,9406
6 Bordeaux 0,5748
7 Italie-No -0,1933
8 AfriqueSud 0,5591
9 Millessima 0,5693
10 1jour1vin-0,9083
11 Nicolas 0,3389
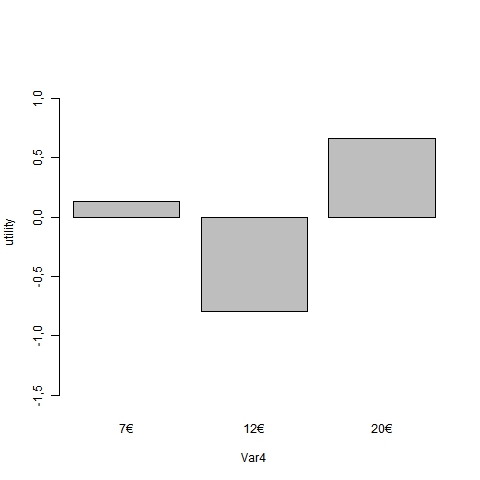
12 7€ -0,901
13 12€ -0,6254
14 20€ 1,5264
15 Médaillor-0,0999
16 NC 0,0999
17 Bio -0,7956
18 NC 0,7956
19 2014 -0,8828
20 2011 0,8828
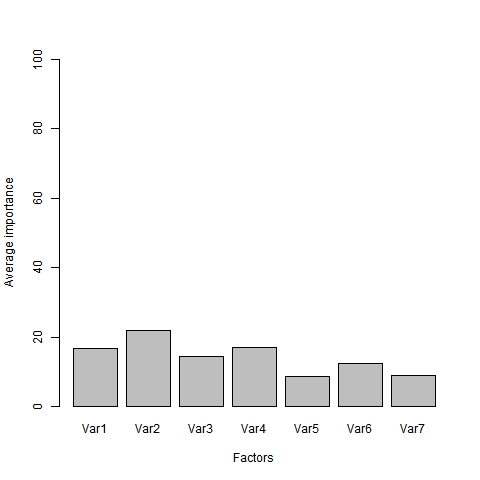
[1] “Average importance of factors (attributes):”
[1] 17,58 18,68 14,39 20,87 8,40 10,53 9,54
On notera d’emblée u r2 proche de 17,5%, ce qui signifie que l’on reconstitue imparfaitement les préférences mais de manière significative : le test d’analyse de variance l’est à moins de 1 pour 1000. D’autre facteurs interviennent mais n’ont pas été pris en compte : forme de la bouteille, étiquette, Chateau etc. Les path-worth représente le gain en terme de rang qui est obtenus : les valeurs négative signifie simplement qu’on améliore le classement avec la présence de la modalité. Par conséquent le profil préféré est un vin sec, de type bourgogne, vendu par 1j1vin à 7 euros, bio et ayant reçu une médaille, et plutôt jeune. On s’aperçoit que le prix pèse vous 21% suivi par l’origine et le type de vin, la médaille et le millésime comptant pour peu.
La commande produit aussi de manière automatique les graphiques de profil d’utilité correspondants :
Poursuivons la procédure. Ces résultats généraux sont une chose, mais on souhaite avoir des résultats plus individualisés. Les commandes suivantes nous permettent de générer un fichier des utilités individuelles :
upartial<-caPartUtilities(MemoireVin_rank4$concept,design_vin2,label)
newData <- as.data.frame(upartial)
newData
names(newData) <- make.names(names(newData))
L’analyse conjointe à ce stade est achevée et nous pouvons en exploiter les résultats. A titre d’exemple on peut s’interroger sur le poids des attributs dont on se dit qu’ils peuvent varier selon le degré d’expertise des consommateurs. Pour vérifier cette proposition, il va falloir d’abord transformer les utilités des modalités en importance des attributs. La formule générale est simplement Wk = abs(Min(ki)-Max(ki)/ somme(abs(Min(ki)-Max(ki)), k représente l’attribut, i les modalités des attributs. Le code est simple même si un peu lourd.
#calcul des importances
MemoireVin_rank$x_type<-abs(MemoireVin_rank$Doux-MemoireVin_rank$sec)
MemoireVin_rank$x_Origine<-abs(MemoireVin_rank$Bourgogne-MemoireVin_rank$Afrique.du.Sud)
MemoireVin_rank$x_Enseigne<-abs(MemoireVin_rank$Millessima-MemoireVin_rank$Nicolas)
MemoireVin_rank$x_Prix<-abs(MemoireVin_rank$X7.-MemoireVin_rank$X20.)
MemoireVin_rank$x_Medaille<-abs(MemoireVin_rank$Médaille.d.or-MemoireVin_rank$NC)
MemoireVin_rank$x_Bio<-abs(MemoireVin_rank$Bio-MemoireVin_rank$NC)
MemoireVin_rank$x_Millessime<-abs(MemoireVin_rank$X2014-MemoireVin_rank$X2011)
MemoireVin_rank$x=MemoireVin_rank$x_type+MemoireVin_rank$x_Origine+MemoireVin_rank$x_Enseigne+MemoireVin_rank$x_Prix+MemoireVin_rank$x_Medaille+MemoireVin_rank$x_Bio+MemoireVin_rank$x_MillessimeMemoireVin_rank$x_type<-MemoireVin_rank$x_type/MemoireVin_rank$x
MemoireVin_rank$x_Origine<-MemoireVin_rank$x_Origine/MemoireVin_rank$x
MemoireVin_rank$x_Enseigne<-MemoireVin_rank$x_Enseigne/MemoireVin_rank$x
MemoireVin_rank$x_Prix<-MemoireVin_rank$x_Prix/MemoireVin_rank$x
MemoireVin_rank$x_Medaille<-MemoireVin_rank$x_Medaille/MemoireVin_rank$x
MemoireVin_rank$x_Bio<-MemoireVin_rank$x_Bio/MemoireVin_rank$x
MemoireVin_rank$x_Millessime<-MemoireVin_rank$x_Millessime/MemoireVin_rank$x
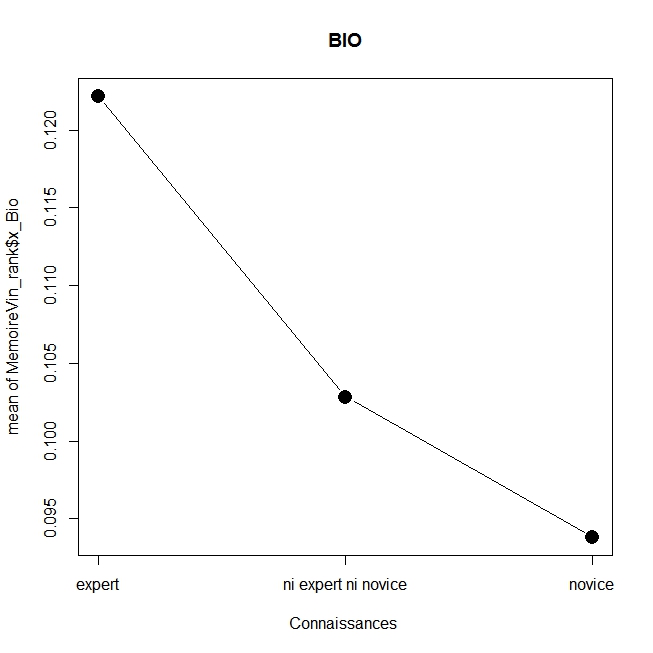
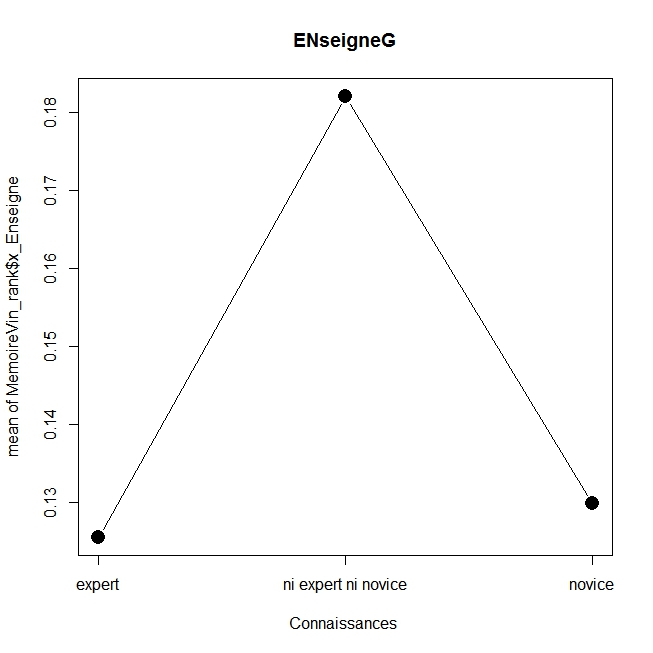
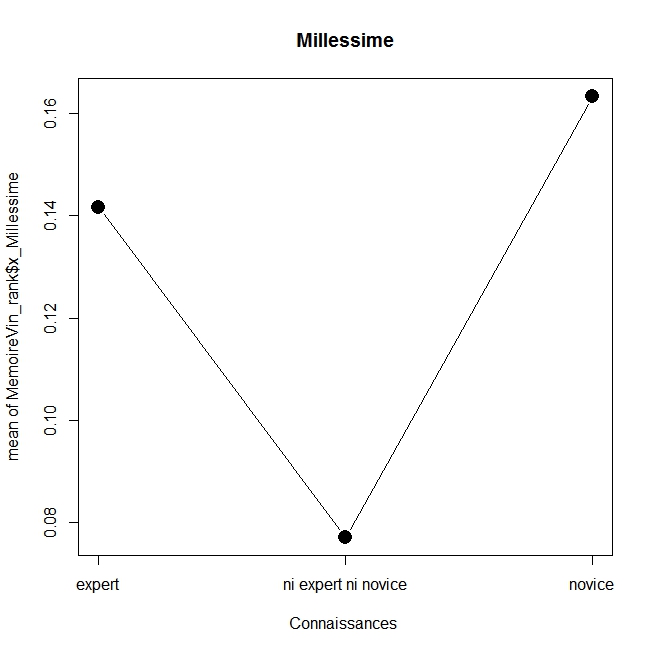
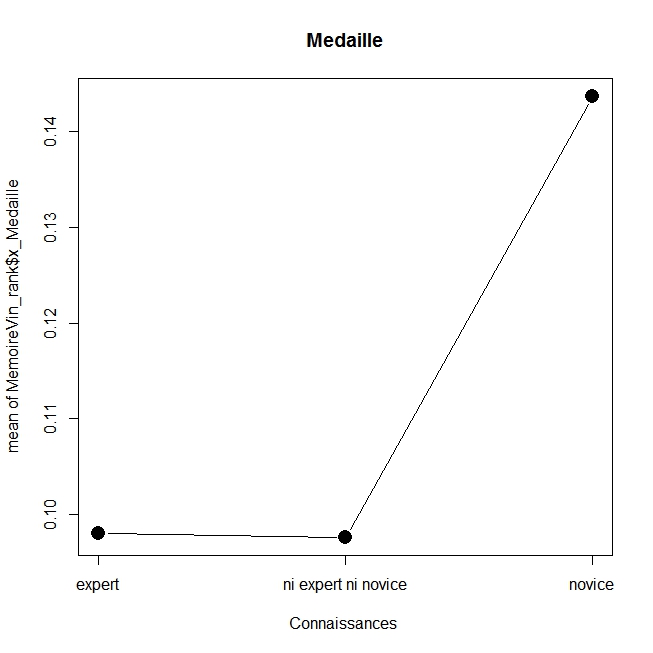
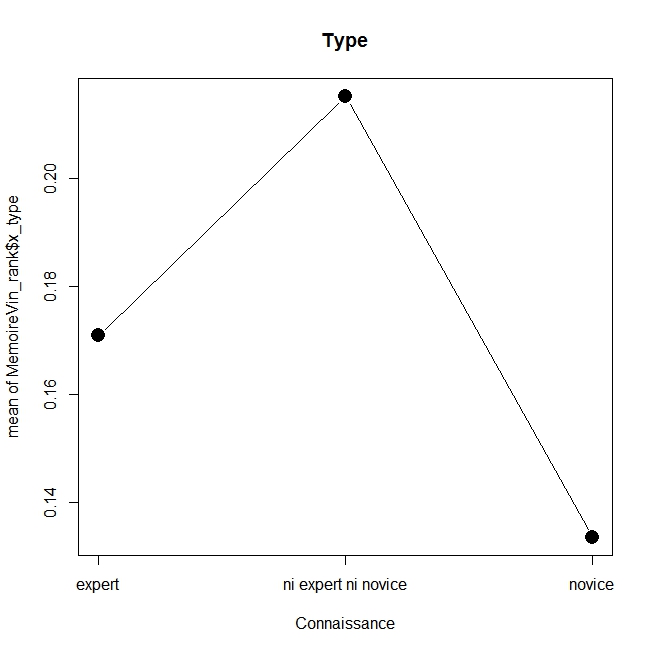
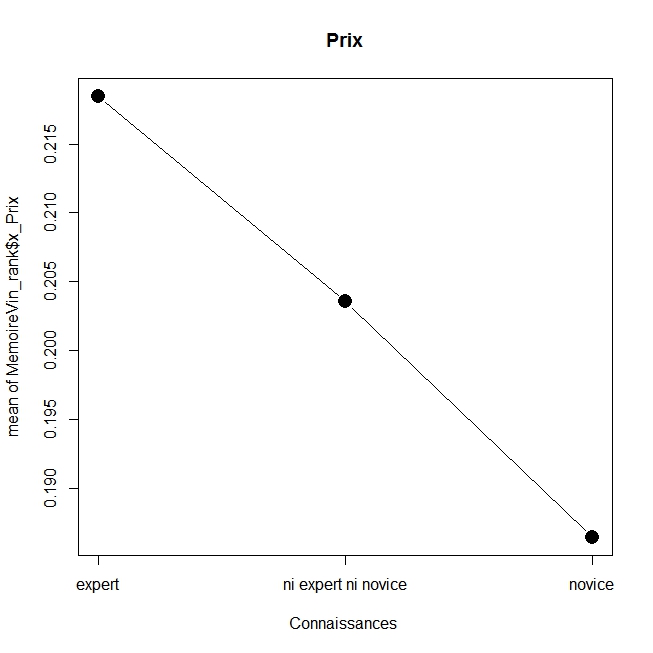
En voici les résultats réalisé avec la commande plotMeans du package Rcmdr (la fonction x11() permet d’ajouter les graphiques), on s’apercevra que ceux qui se sentent experts donne un poids plus important au caractère bio et au prix, tandis que les novices accordent plus d’attention à la médaille, au millésime et à l’origine, alors que ceux qui se sentent un degré modéré d’expertise favorisent l’enseigne et le type de vin. Sans aller plus loin dans l’analyse on obtient un résultat général clair : on n’utilise pas les mêmes critères selon le niveau d’expertise, ce qui est assez logique. On laissera au lecteur le soin d’aller plus loin.
x11()
plotMeans(MemoireVin_rank$x_type, MemoireVin_rank$EXPERTISE_PERCUE, error.bars=”none”,xlab=”Connaissance”,main=”Type”,cex.lab=1)
x11()
plotMeans(MemoireVin_rank$x_Origine, MemoireVin_rank$EXPERTISE_PERCUE, error.bars=”none”,xlab=”Connaissance “,main=”Origine”,cex.lab=1)
x(11)
plotMeans(MemoireVin_rank$x_Enseigne, MemoireVin_rank$EXPERTISE_PERCUE, error.bars=”none”,xlab=”Connaissances “,main=”ENseigneG”,cex.lab=1)
x11()
plotMeans(MemoireVin_rank$x_Medaille, MemoireVin_rank$EXPERTISE_PERCUE, error.bars=”none”,xlab=”Connaissances “,main=”Medaille”,cex.lab=1)
x11()
plotMeans(MemoireVin_rank$x_Bio, MemoireVin_rank$EXPERTISE_PERCUE, error.bars=”none”,xlab=”Connaissances “,main=”BIO”,cex.lab=1)
x11()
plotMeans(MemoireVin_rank$x_Millessime, MemoireVin_rank$EXPERTISE_PERCUE, error.bars=”none”,xlab=”Connaissances “,main=”Millessime”,cex.lab=1)
x11()
plotMeans(MemoireVin_rank$x_Prix, MemoireVin_rank$EXPERTISE_PERCUE, error.bars=”none”,xlab=”Connaissances “,main=”Prix”,cex.lab=1)
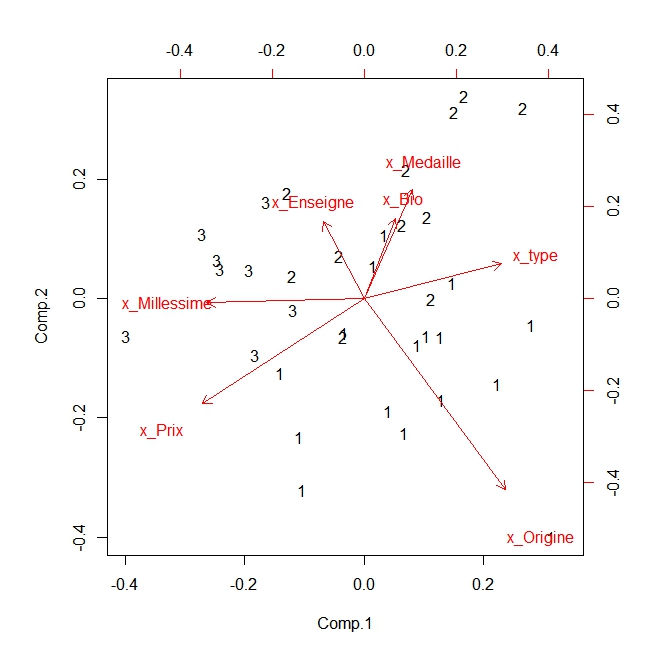
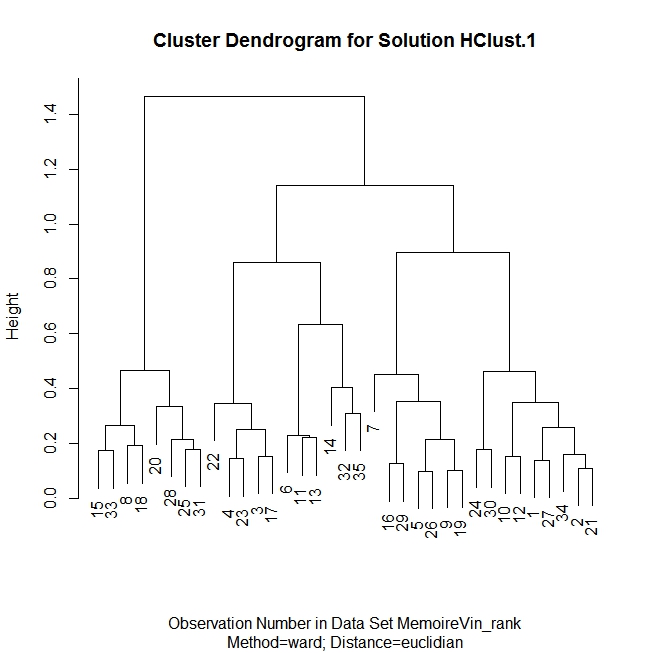
Généralement on cherchera à segmenter notamment pour identifier les groupes de consommateurs qui partagent les mêmes attentes. Ici on emploie les fonctions d’analyse hierarchique ( méthode de ward) fourni par l’interface graphique Rcmdr qui a déja été appelée, en choisissant la solution à trois groupes et en l’illustrant par le biplot. le code correspondant est le suivant ( mais en fait on s’est contenté d’utiliser le menu)
HClust.1 <- hclust(dist(model.matrix(~-1 +
x_Bio+x_Enseigne+x_Medaille+x_Millessime+x_Origine+x_Prix+x_type,
MemoireVin_rank)) , method= "ward")
plot(HClust.1, main= "Cluster Dendrogram for Solution HClust.1", xlab=
"Observation Number in Data Set MemoireVin_rank",
sub="Method=ward; Distance=euclidian")
summary(as.factor(cutree(HClust.1, k = 3))) # Cluster Sizes
by(model.matrix(~-1 + x_Bio + x_Enseigne + x_Medaille + x_Millessime +
x_Origine + x_Prix + x_type, MemoireVin_rank), as.factor(cutree(HClust.1, k
= 3)), colMeans) # Cluster Centroids
biplot(princomp(model.matrix(~-1 + x_Bio + x_Enseigne + x_Medaille +
x_Millessime + x_Origine + x_Prix + x_type, MemoireVin_rank)), xlabs =
as.character(cutree(HClust.1, k = 3)))
les profils apparaissent dans le tableau : le groupe 1 donne plus de poids à l’origine et au type, le groupe 2 à l’enseigne et au caractère bio, le groupe 3 au prix et au millesime. O peux penser que le premier favorise les goûts de l’individu, le second le style d’achat, et le troisième un certain rapport qualité/prix. On retrouve ainsi ce grand classique des avantages recherchés!
INDICES: 1
x_Bio x_Enseigne x_Medaille x_Millessime x_Origine x_Prix
0.07147493 0.10822056 0.09169431 0.11697915 0.22503436 0.19621573
x_type
0.19038097
————————————————————
INDICES: 2
x_Bio x_Enseigne x_Medaille x_Millessime x_Origine x_Prix
0.17373411 0.19015292 0.15400115 0.05344901 0.07003827 0.16861833
x_type
0.19000620
————————————————————
INDICES: 3
x_Bio x_Enseigne x_Medaille x_Millessime x_Origine x_Prix
0.07657425 0.13635953 0.12456815 0.29134291 0.04337232 0.25255357
x_type
0.07522927

 L’objectif du cours est de donner une culture quantitative élargie aux étudiants, leur laissant le soin d’approfondir les méthodes qui pourraient être utilisées dans le cadre de leurs projets de recherche.
L’objectif du cours est de donner une culture quantitative élargie aux étudiants, leur laissant le soin d’approfondir les méthodes qui pourraient être utilisées dans le cadre de leurs projets de recherche. La perceuse du voisin est le modèle même de l’utopie collaborative. Mettre à disposition des autres des équipements dont on a pas forcément l’usage est une évidence durable et économique : augmenter le taux d’usage des appareils qu’on utilise à l’occasion semble être méritoire. Si cet échange est gratuit, qu’une application en réduit les coûts de transaction, c’est à une véritable économie contributive qu’on donne naissance, et on espère que ces circuit assure une vaste circulation, dont une des utopie est l’anthropologie de la
La perceuse du voisin est le modèle même de l’utopie collaborative. Mettre à disposition des autres des équipements dont on a pas forcément l’usage est une évidence durable et économique : augmenter le taux d’usage des appareils qu’on utilise à l’occasion semble être méritoire. Si cet échange est gratuit, qu’une application en réduit les coûts de transaction, c’est à une véritable économie contributive qu’on donne naissance, et on espère que ces circuit assure une vaste circulation, dont une des utopie est l’anthropologie de la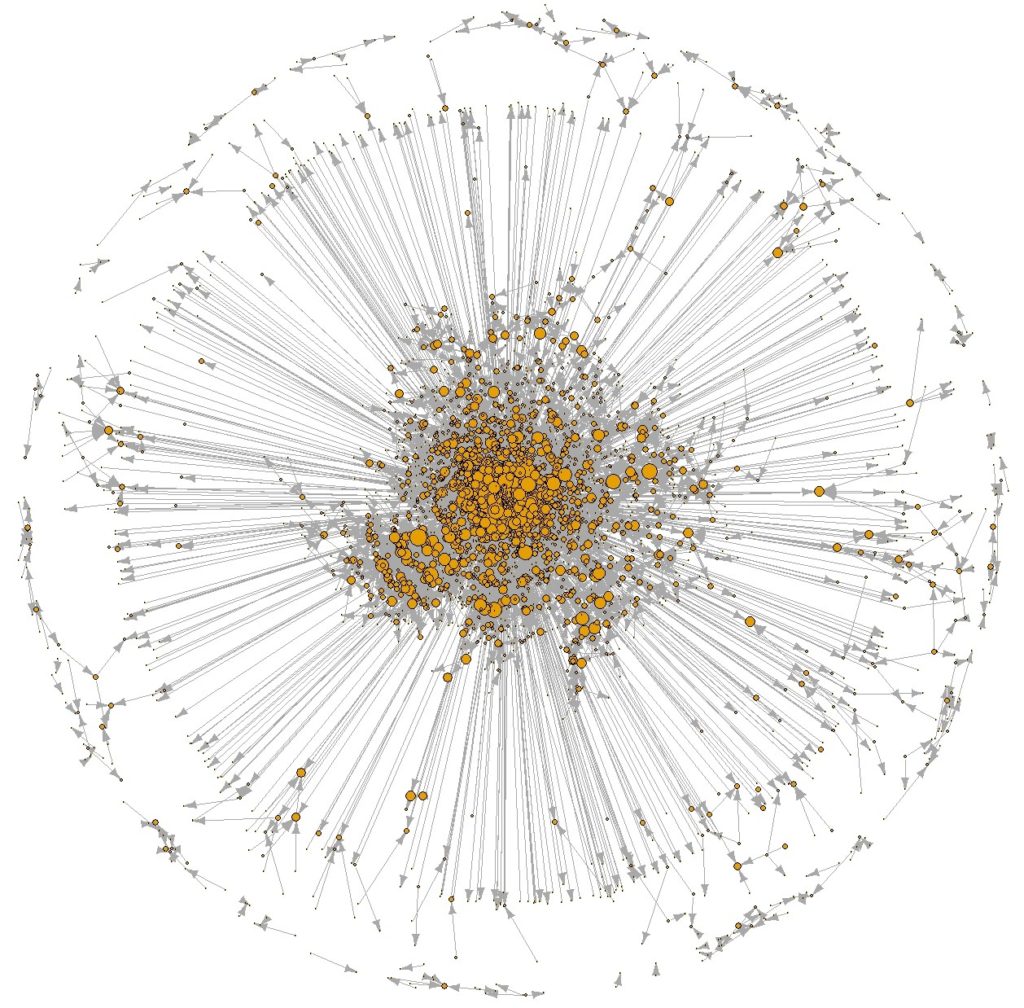
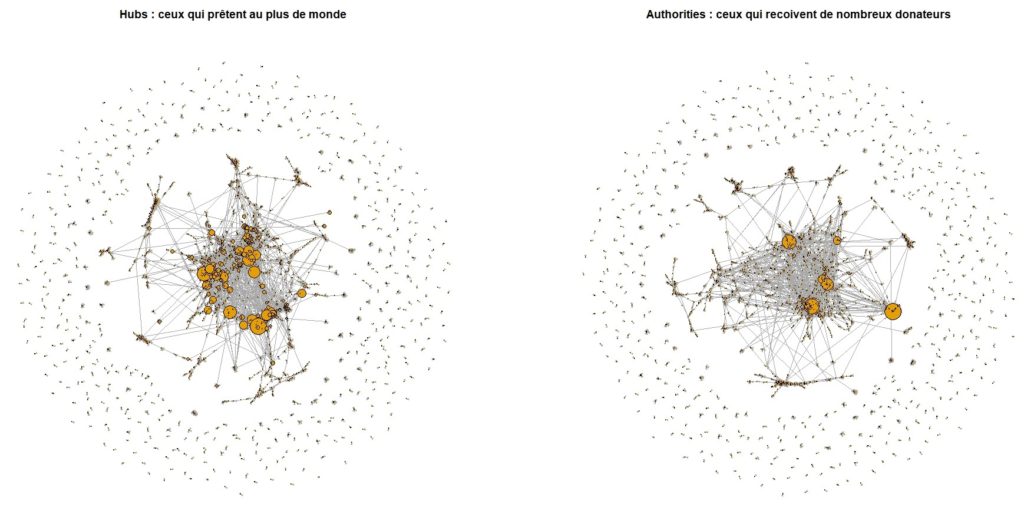

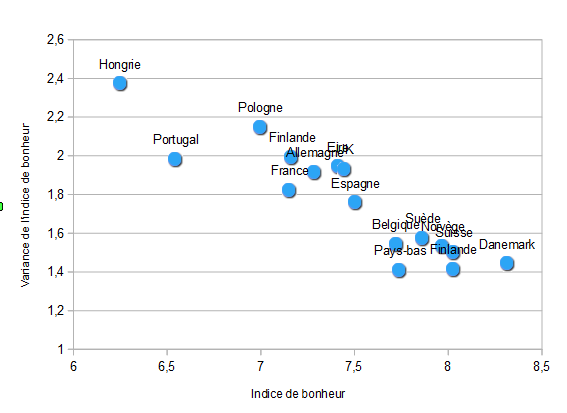
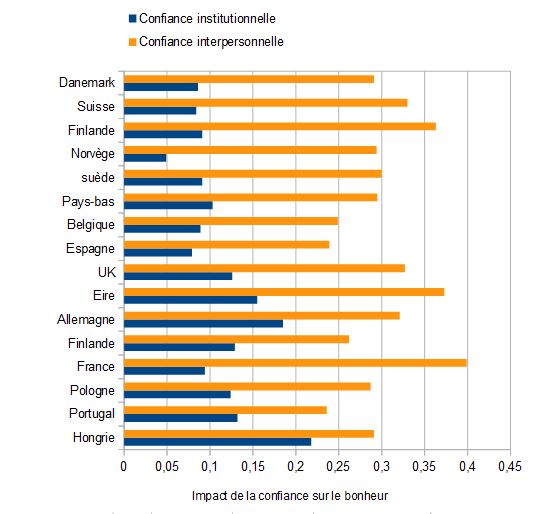
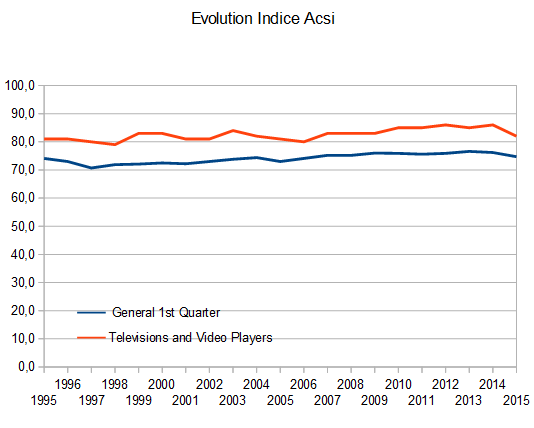
 Il y a des moments de bonheur. Par exemple, celui où on découvre un jeu de données merveilleux et que l’on part à son exploration. Ce jeu de donnée est celui de l’
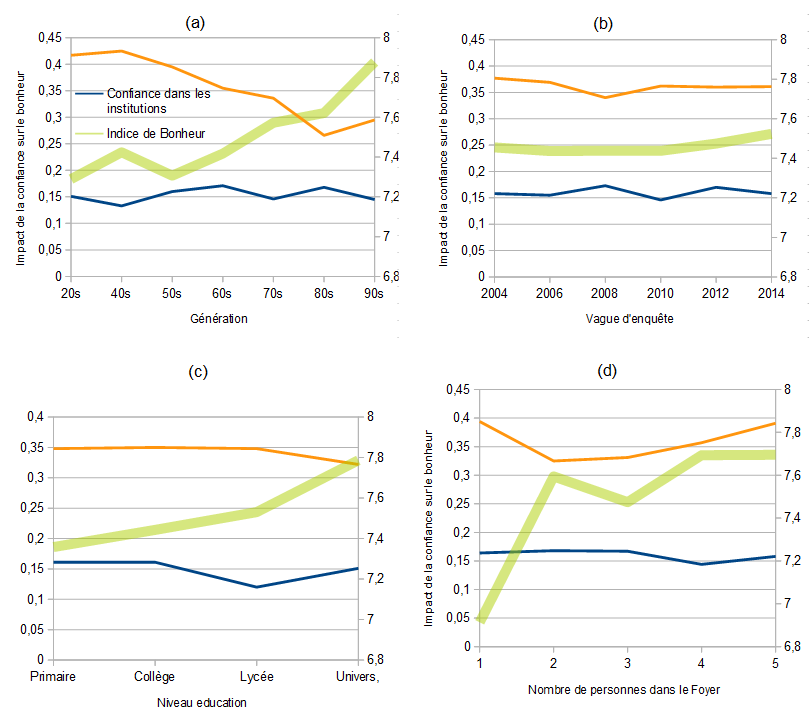
Il y a des moments de bonheur. Par exemple, celui où on découvre un jeu de données merveilleux et que l’on part à son exploration. Ce jeu de donnée est celui de l’ Avoir autant de données pour une presque trivialité peut sembler inutile, sauf si l’on cherche à voir ce qui peut faire varier ce modèle. L’idée est donc simplement d’évaluer ce modèle pour différents groupes. La seule chose à faire est de modifier l’ajustement avec cette ligne :
Avoir autant de données pour une presque trivialité peut sembler inutile, sauf si l’on cherche à voir ce qui peut faire varier ce modèle. L’idée est donc simplement d’évaluer ce modèle pour différents groupes. La seule chose à faire est de modifier l’ajustement avec cette ligne :