
Sur Canal U , aux journées nationales du Management, le 13 novembre . Il y en a pour 79 minutes. C’est la suite du papier publié dans économie et management (n°168, juin 2018) ” méthamorphose digitale du marketing”, un complément. Les slides sont disponibles ici.
Étiquette : Algorithme
Anatomie des échanges collaboratifs
 La perceuse du voisin est le modèle même de l’utopie collaborative. Mettre à disposition des autres des équipements dont on a pas forcément l’usage est une évidence durable et économique : augmenter le taux d’usage des appareils qu’on utilise à l’occasion semble être méritoire. Si cet échange est gratuit, qu’une application en réduit les coûts de transaction, c’est à une véritable économie contributive qu’on donne naissance, et on espère que ces circuit assure une vaste circulation, dont une des utopie est l’anthropologie de la Kula.
La perceuse du voisin est le modèle même de l’utopie collaborative. Mettre à disposition des autres des équipements dont on a pas forcément l’usage est une évidence durable et économique : augmenter le taux d’usage des appareils qu’on utilise à l’occasion semble être méritoire. Si cet échange est gratuit, qu’une application en réduit les coûts de transaction, c’est à une véritable économie contributive qu’on donne naissance, et on espère que ces circuit assure une vaste circulation, dont une des utopie est l’anthropologie de la Kula.
Ce n’est qu’une hypothèse et nous avons encore besoin de comprendre comment s’organisent les cascades de prêts et d’emprunts et de mieux comprendre comment spontanément la circulation des objets s’organisent. Certains se prêtent à l’échange : la perceuse-visseuse, la poussette, le vélo, des barbecue et des gauffriers. D’autres moins. Un défi est ouvert, retrouver dans le Paris Bobo les circuits du don que Malinowski a cru trouver entre la Paouasie, les iles Salomons et les Trobiands.
Par chance, on nous a confié une base de données relevant toutes les transactions effectuées pendant une certaine période ( supérieure à une année) sur une portion substantielle des utilisateurs de la plateformes (disons près de 15% d’entre eux). Ce n’est pas du big data mais assez substantiel : plus de 5000 transactions qui aboutissent ou non ( le taux de transformation est en fait de l’ordre de 30%).
Un premier réflexe est naturellement de représenter graphiquement le réseau constitué par ces échanges. C’est un réseaux directionnel qui associe un prêteur à un emprunteur. Il nous suffit de reformater les données sous la forme de duplets associant le code unique d’un prêteur et celui d’un emprunteur, et de quelques autres attributs définissant la nature de l’objet échangé et la date de l’échange. L’usage direct de igraph et d’un algorithme de force ( KK) via r, permet de produire à peu de frais cette structure. La taille des noeuds est proportionnelle aux nombre de transactions engagées. Au comprend qu’au centre du graphe se trouvent les utilisateurs actifs et que dans la périphéries les utilisateurs occasionnels. On améliorera la représentation en élimant les couches externes (échangeurs avec une à 3 transaction) pour mieux examiner la structure du macro-composant.
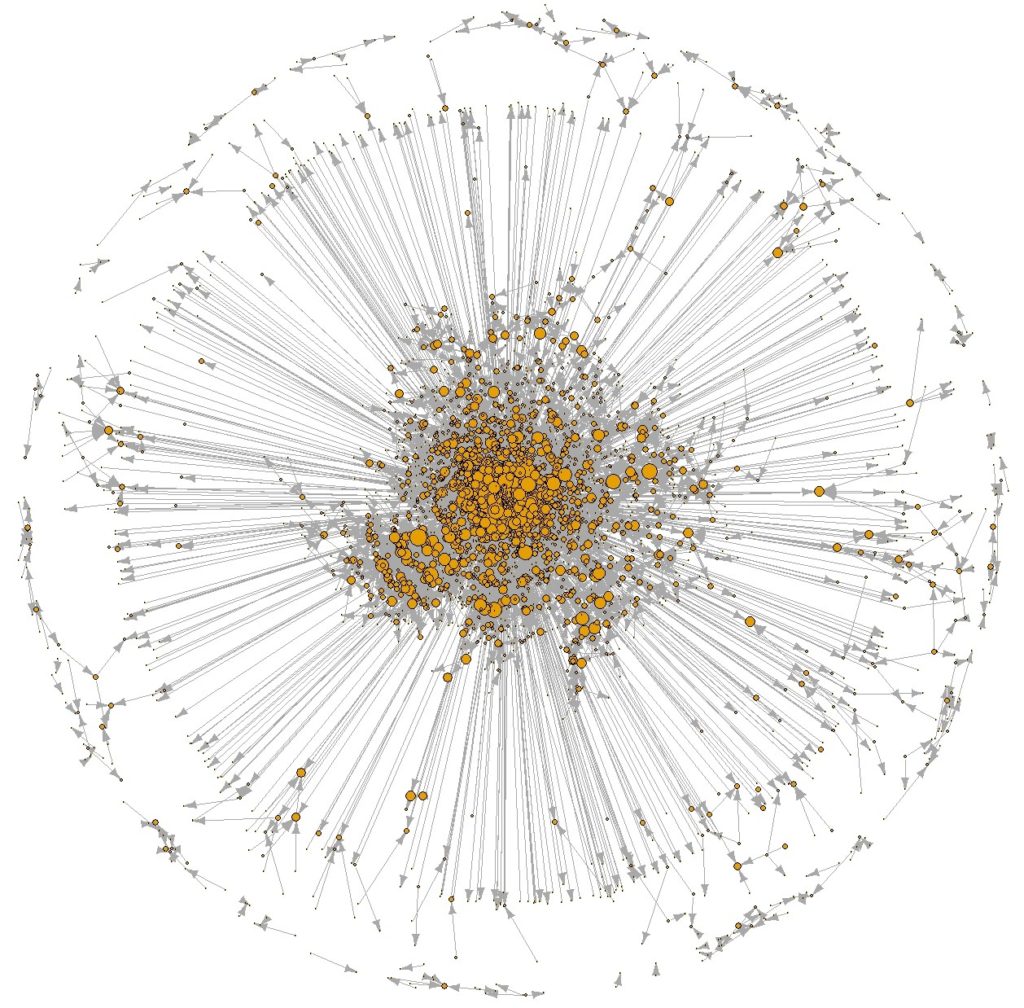
figure 1 : réseau des engagements de transactions
Le phénomène principal est en fait la diversité des statuts : si certains échangent beaucoup et d’autres échangent moins, on s’aperçoit vite qu’ils diffèrent aussi par ceque certains prêtent plus souvent qu’ils n’en empruntent. Nous ne sommes pas dans un espace de marché réciproques (où une contrepartie monetaire est échangée) mais un espace asymétrique où des prêteurs principaux et des emprunteurs net doivent trouver un équilibre à nombre d’objets offerts constant ou croissant. Nous ne développerons pas plus cette aspect essentiel de la dynamique des réseaux d’échange et de leur croissance, pour nous concentrer sur des questions de structure.
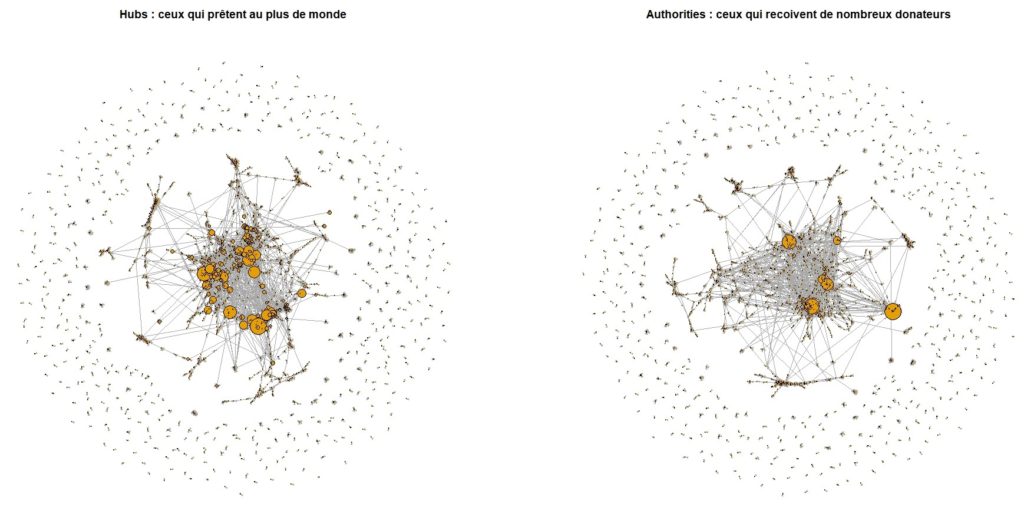
Pour caractériser cette différenciation des rôles ( prêteur vs emprunteurs) nous pouvons employer le modèle HITS de Jon Keinberg qui permet de scorer le caractère de Hub ou d’autorité des nœuds d’un réseau. Un hub est un site qui pointe vers de nombreux sites qui ont une autorité. Il permet à chacun de trouver le meilleur chemin. Une autorité est un site vers lequel pointent de nombreux hub. Il est reconnu comme un point d’intérêt par la plupart des carrefours. Ces notions précédent et amplifie le concept du PageRanks et rendent compte de la différenciation des rôles dans les réseaux digitaux.
Dans l’économie du partage les hubs délivrent une grande variété de biens à des emprunteurs fréquents; les autorités sont ces emprunteurs réguliers qui assurent les emprunts auprès des propriétaires les plus populaires. Les uns et les autres forment en quelques autres le moteur du système. Leur dynamique est le coeur nucléaire de la collaboration, ils amènent rapidement à atteindre le seuil critique.
Une fonction permet de représenter ces deux aspects des noeuds : sont-il plutôt des hubs où des autorités, des donneurs universels et receveurs généraux. En voici les deux cartes. On s’aperçoit dans la périphérie du nuage des transactions uniques, aux coeur du réseaux on s’aperçoit que les hub sont plus nombreux que les autorités : peu d’emprunteurs en dernier ressort absorbent l’offre dominante de hubs plus nombreux.
A ce stade nous sommes encore descriptif : les données que nous avons traitées sont jusqu’à présent moins des transaction que les entames de transaction, et on dispose d’une information: la transaction qui s’engage se conclue-t-elle? Nous connaissons la structure des relations, nous pouvons caractériser chaque acteur comme Hub ou Autorité, nous savons si une transaction engagée entre deux acteurs est conclue, un petit modèle prédictif est bienvenu. Quels sont les facteurs qui facilitent la transaction ?
Un premier évident est celui de la nature du produit échangé. Nous avons fait des tests préliminaires et il semble bien que ce soit déterminant, mais un peu de travail est encore nécessaire pour codifier les objets et mieux tester cette source de succès.
Le second facteur semble aussi naturel : la transaction se fera en fonction des caractéristiques des acteurs, et notamment leur score de hub et d’autorité. Ceci représente l’hypothèse du “social embedness” qui enonce que les acteurs ne sont pas homogènes et que leur pouvoir dépend de leur inclusion sociale. C’est notre hypothèse principale.
Un troisième facteur est lui relatif à l’expérience : quand des acteurs répètent l’échange, en principe si tout se passe bien la confiance s’installe avec l’habitude et on s’attend à ce que la probabilité que la transaction réussisse soit plus grande.
Testons cela par un modèle de régression logistique dans lequel la variable dépendante est le caractère achevé ou non de l’échange, et les déterminants sont le nombre d’échanges déjà réalisés, le score de hub du prêteur, et celui d’autorité pour caractériser l’emprunteur.
(Intercept) -1.388 0.0391 -35.557 ****
authority_score. 0.355 0.1809 1.963 **
hub_score. -0.492 0.3121 -1.578 *
NBdePrets 0.036 0.0059 6.264 ****
* 10% ** 5% *** 1% ***** <<1%
Les résultats sont clair : plus grand est le nombre d’échange entre deux utilisateurs et plus grande est la probabilité de réalisation. Plus élevé est le score d’autorité plus l’échange a de chance de se réaliser : les emprunteurs fréquents réalisent mieux leurs demandes, ils ont sans doute appris à utiliser la plateforme, on mesure ainsi un effet d’apprentissage, une autre interprétation c’est qu’échangeant souvent ils développent une expérience qui est un signal de confiance. En revanche le score de hub ne semble pas influencer la probabilité de réalisation de l’échange. Une hypothèse est que si les hubs bénéficient d’un effets de réputation, ils souffrent aussi d’un effet de compétition. Offrant le plus de biens aux meilleurs emprunteurs, leurs biens, uniques, sont mis en concurrence, et certains emprunteurs échouent. Les deux effets se neutraliseraient.
Nous n’irons pas plus loin dans la discussions. Les éléments quantitatifs sont encore assez bruts, la méthode générale est données, nous devons en affiner l’application. Mais déjà des résultats émergent pour comprendre comment les flux de l’échange s’organisent et plus précisément comment la structure sociale peut déterminer au travers de la position des échangeurs la probabilité qu’un échange se produise.
Et voilà qu’avec quelques ligne de r, nous refaisons le voyage des argonautes.
Satisfaction à l’égard des moteurs de recommandation : la transparence optimale
 C’est une idée ancienne. Le mieux dans la transparence n’est pas le plus, c’est plutôt un clair-obscur, assez clair pour que la lumière traverse, assez obscur pour qu’on y devine un relief.
C’est une idée ancienne. Le mieux dans la transparence n’est pas le plus, c’est plutôt un clair-obscur, assez clair pour que la lumière traverse, assez obscur pour qu’on y devine un relief.
Il en est de même pour la transparence des algorithmes. Les utilisateurs réagissent le mieux à une information épurée, simplifiée, qui donne les principes sans brouiller avec les détails. Le simple plus que le complet.
Ce papier, publié dans la nouvelle et intéressante revue Management et DataScience en teste l’hypothèse. S’il est modeste dans la méthode et le principe ses résultats sont très net. Cela a des conséquences en matière de design des sites et des applications. Donner des éléments clés qui favorise l’autonomie de jugement ( dois-je faire confiance à ce type d’algorithme ?) et la connaissance de risque éventuel, sans demander un effort exorbitant. Cela cependant ne résout pas la question du contrôle effectif des algorithme qui demande une connaissance approfondie des détails. On comprend que celle-ci n’est pas à la charge des consommateurs, mais des organismes spécialisés dans la défense des droits et des consommateurs, la recherche académique, ou de régulation. La transparence est un arrangement institutionnel.
PS : au passage soulignons que cette publication est le résultat du mémoire de master marketing à Nanterre de Pauline Vautrot.
Marketing Digital
 Ce cours est donné principalement dans le cadre de la Licence 3 à l’UFR SEGMI à Paris Nanterre. . L’article ” La métamorphose digitale du marketing” synthétise le propos.
Ce cours est donné principalement dans le cadre de la Licence 3 à l’UFR SEGMI à Paris Nanterre. . L’article ” La métamorphose digitale du marketing” synthétise le propos.
Le support de cours est disponible ici.
Thématique
Le thème général pour la session 2018 portera sur le marketing des plateformes, et plus particulièrement sur l’emploi des données et des algorithmes dans les stratégies marketing. L’étude des plateformes est privilégié. Il s’appuie en partie sur le livre “Plateformes : Sites collaboratifs, marketplaces, réseaux sociaux… Comment ils influencent nos choix“.
Évaluation :
Le travail est individuel.
Il est à rendre pour le 15 décembre 2020.
Syllabus
Le découpage du cours suit les grandes problématiques marketing
1- introduction : tendances de la consommation et modèle de plateforme
-
- tendance de consommation : voir présentation ci-dessous
- Modèles de plateformes : les slides et une vidéo.
- le rôle des algorithmes.
2 - Segmentation et versants de marché
-
- Segmentation par avantages recherchés ( à partir de l’étude UM Wave)
- Marchés multi-versants et marchés d’appariement - gestion des sites de rencontre.
3 - La relation à la marque et son positionnement dans l’espace digital
-
- Analyse de la réputation et du sentiment
-
- Points de contact et interaction multicanale
- Réclamation et gestion des litiges ( cas Airbnb)
4 - Les systèmes d’influence et de discipline des consommateurs
-
- CGU, modération, trolling et sanctions - twitter et presse
-
- Les systèmes de notation et d’avis - trip advisor
- Nudge et gamification ( fomo sur booking), système de jetons
5 - La gestion d’une production et d’une distribution à la demande. Simplicité.
-
- Echelles et densité : la gestion du crowdsourcing - plateformes d’innovation
-
- Systèmes de recommandation - le cas de netflix, amazon, spotify
- le rôle du machine learning (La valorisation des photo de Flickr)
6 - Les mécanismes de pricing
-
- Le surge pricing de Uber
-
- Les modèles d’enchères - Ebay
-
- Les modèles conventionnels - Blablacar ( prix recommandé)
- Problèmes de discrimination. ( Airbnb)
7 - Publicité programmatique
- CRM et DMP
- modèle de ciblage et reciblage
Présentation d’introduction :
Série Xerfi - Fnege : datas, plateformes et algorithmes.
 Une des vidéos date un peu, les deux autres sont toutes fraîches, elles sont complémentaires car elles traitent sous trois angles, les données, les algorithmes et les plateformes, cette réalité de nouvelles formes d’organisations fondées sur un traitement massif de l’information.
Une des vidéos date un peu, les deux autres sont toutes fraîches, elles sont complémentaires car elles traitent sous trois angles, les données, les algorithmes et les plateformes, cette réalité de nouvelles formes d’organisations fondées sur un traitement massif de l’information.
Ces vidéos ont été tournées dans le cadre du partenariat de Xerfi canal et de la FNEGE. On en retrouvera des dizaines d’autres sur tous les sujets de la gestion, des marchés et des organisations. Un belle série.
Modèle de plateformes
Algorithmes
Les modèles du bigdata
Algorithmic accountability - Work in progress
 Il y a peu les géants du digital lançaient le partenariat pour l’IA . C’est peut être ce colloque à la NYU qui en a cristallisé l’idée. C’est déjà dans le livre de Franck Pasquale. La question du rôle social des algorithmes et de leur responsabilité, notamment celle de rendre des comptes devient centrale dans nos sociétés. Elle l’est en particulier pour les pratiques de marketing qui s’expriment de plus en plus via leurs calculs sur des volumes toujours accrues de données, les plateformes en sont le champs d’expression principal.
Il y a peu les géants du digital lançaient le partenariat pour l’IA . C’est peut être ce colloque à la NYU qui en a cristallisé l’idée. C’est déjà dans le livre de Franck Pasquale. La question du rôle social des algorithmes et de leur responsabilité, notamment celle de rendre des comptes devient centrale dans nos sociétés. Elle l’est en particulier pour les pratiques de marketing qui s’expriment de plus en plus via leurs calculs sur des volumes toujours accrues de données, les plateformes en sont le champs d’expression principal.
Recommander des produits, des relations, évaluer des risques, définir des prix, calculer des parcours, lancez des alertes personnalisées, qualifier des offres, commandez des machines, la panoplie des outils ne fait que s’étendre et se raffiner. Ces pratiques ne font-elles que ce qu’elles doivent faire? Entrainent-elle pas des réponses de ses sujets? Lesquelles? Quels sont leurs effets secondaires?
De l’économie collaborative au gouvernement algorithmique des plateformes
 Ce texte résume l’intervention réalisée dans le cadre de la Conférence Internationale de Gouvernance CIG 2016 à l’Université de Montpellier : Gouvernance et gouvernementalité à l’heure du big data : quels enjeux pour les entreprises ? La version originale de cet article a été publiée sur The Conversation.
Ce texte résume l’intervention réalisée dans le cadre de la Conférence Internationale de Gouvernance CIG 2016 à l’Université de Montpellier : Gouvernance et gouvernementalité à l’heure du big data : quels enjeux pour les entreprises ? La version originale de cet article a été publiée sur The Conversation.
Avec le développement de l’économie collaborative, ou d’économie on-demand, le modèle de plateforme prend un nouvel élan. On l’a découvert avec les plateformes-produits, il s’est conforté avec les marketplaces, il s’épanouit avec les réseaux sociaux. Désormais il règle les échanges de services et le prêt des biens. Une grande partie des 150 licornes (start-up valant plus d’un milliard de dollars) est constituée par des plateformes, on en dénombre plusieurs milliers, dont Uber, BlaBlaCar ou Ola dans le transport, Airbnb ou Booking.com pour hébergement à courte durée, Oscaro, Lending Club ou Indiegogo dans le crowdfunding, Amazon, Alibaba pour les places de marché, mais aussi Esty dans une version plus collaborative, Deliveroo ou Hero delivery dans la logistique du dernier kilomètre, Fiverr et Taskrabbit pour les services à domicile.
Du crowdsourcing et des algorithmes
Le propre des plateformes réside dans deux éléments. Le premier est une généralisation du crowdsourcing qui, ouvrant très largement l’approvisionnement en actifs productifs, en travail et en consommations intermédiaires, donne une place importante à des acteurs que l’on peut qualifier d’amateurs. Le second est du recours intensif aux algorithmes pour assurer la coordination des activités à une échelle très importante (des centaines de millions d’individus) et très fine du point de vue de l’espace et du temps. La combinaison de ces deux éléments conduit à un modèle d’organisation d’un type nouveau, fondé sur la maîtrise des algorithmes qui pose des questions de gouvernance, d’autant plus fortes que les machines sont faillibles.
Le moteur de croissance des plateformes s’analyse au travers de la combinaison de plusieurs mécanismes économiques. Le premier est celui du crowdsourcing et il se révèle dans la capacité à mobiliser des actifs sous-utilisés, du travail parfois non rémunéré et de l’information et des idées partagées. Il engendre un second mécanisme de la longue traîne, plus justement décrit par la notion d’économie de la diversité. Le troisième est l’interaction positive entre les populations qui constituent les différents versants de marché : l’attractivité de la plateforme sur le versant client est d’autant plus grande que la diversité des offres est forte et réciproquement.
Elle est amplifiée par la maîtrise des capacités d’appariement (matching markets) qui permettent de résoudre la faiblesse d’une offre trop large et trop diverse pour les capacités cognitives des demandeurs, par le biais de score d’appariement (comme sur les plateformes de rencontre) et de moteurs de recommandation (comme dans le cas les places de marchés). L’ensemble produit des externalités de réseaux et de standard qui soutiennent la politique de crowdsourcing.
Gouvernementalité algorithmique
L’analyse économique permet de rendre compte a posteriori des succès des plateformes, mais dit peu de la manière dont ils sont menés.
C’est dans la manière dont les plateformes gouvernent leurs populations qu’on peut trouver une réponse. Avec le concept de gouvernementalité de Michel Foucault, définit rapidement comme l’influence sur les conduites qui transforme les populations en ressources, un cadre d’analyse cohérent peut être formulé. La gouvernementalité se manifeste par trois grands éléments : l’architecture des plateformes qui capacite ou restreint l’action de ses membres et des populations ; une capacité normative et de surveillance -une police ; un dispositif incitatif qui stimule l’activité des acteurs individuels et mobilise les foules.
La spécificité de ces politiques est d’être largement algorithmique, se nourrissant d’un flux de données important (le big data) qui à la fois permet de produire la connaissance nécessaire et la mise en œuvre des politiques dans le flux des microdécisions prises par l’organisation et les individus. Un mécanisme comme le surge pricing de Uber en est un exemple remarquable : à l’échelle de quelques minutes et d’un quartier, Uber peut faire varier les tarifs en fonction de l’offre de VTC et de la demande, dans le but principal de limiter l’attente à moins de cinq minutes.
Le calcul n’est pas neutre
On a tendance à surestimer leur efficacité et leur neutralité. Ils produisent des effets de dispersion des prix, de polarisation des opinions, de discrimination sociale. Autant d’effets que leurs concepteurs n’ont pas envisagés. C’est le fruit d’une forte dépendance aux données : les paramètres des algorithmes dépendent des données qu’ils traitent, et certains groupes d’acteurs peuvent les troubler. Le calcul qu’ils produisent n’est pas neutre, son résultat est souvent performatif et les populations qui en sont la cible s’y adaptent par une sorte de social computing.
Les effets de ranking en sont un exemple, le classement renforçant la performance. Des effets inattendus, parfois néfastes, sont observés : extrême variance des prix de marchés, biais de sélection, polarisation des opinions, ségrégation sociale. C’est ce qu’on peut appeler la politique des algorithmes et qu’on définit comme l’effet résiduel et non intentionnel de la gouvernementalité.
Les plateformes font ainsi naître un double risque : celui d’une interférence dans les libertés et celui des externalités sociales liées à la construction même des algorithmes. Cette analyse conduit à s’interroger sur la gouvernance des plateformes et les mécanismes qui permettent de gouverner le gouvernement des plateformes. Quelle politique de confidentialité des données personnelles ? Quel degré de transparence des algorithmes ? Quel degré de participation des usagers à la conception et aux pilotages de ces modèles ? Quel degré de régulation par la puissance publique ?
Avec leur surgissement et leur déploiement planétaire, ces questions deviennent clés. Elles justifient que l’idée de redevabilité algorithmique soit de plus en plus élaborée, et surtout mise en œuvre.
Référence des travaux présentés : C. Benavent (2016) « Plateformes : sites collaboratifs, marketplaces, réseaux sociaux… Comment ils influencent nos choix », Fyp.
![]()
Christophe Benavent, Professeur Sciences de Gestion, Université Paris Ouest Nanterre La Défense – Université Paris Lumières
Plateformes :
 Sites collaboratifs, marketplaces, réseaux sociaux… Comment ils influencent nos choix
Sites collaboratifs, marketplaces, réseaux sociaux… Comment ils influencent nos choix
Il est là et en librairie. Pour l’accompagner cette rubrique où on retrouvera des réflexions autour et au delà du livre ainsi que l’ébauche de chapitres qui n’ont pas été (encore) écrits : es plateformes et le travail, utopie et idéologie des plateformes, politiques publiques des plateformes…
Mentions presse :
- 20mn : entretien 16 juin ( page conso collab)
- Bfm.tv : Lundi 20 juin -14-35 direct
- La revue du digital : “Les gens les plus simples s’approprient les plateformes de manière très efficace”
- La Liberté : Ces algorithmes pas si futés
Community Management Cours
 C’est un cours donné à l’ESC La Rochelle qui déborde largement la fonction de community management, et s’intéresse plus largement à l’usage des plateformes sociales dans le cadre des stratégie marketing qu’il s’agisse de maintenir des communautés de marques, d’amplifier la communication, d’acquérir de nouveaux clients. Sa perspective est celui d’une économie politique de plateformes.
C’est un cours donné à l’ESC La Rochelle qui déborde largement la fonction de community management, et s’intéresse plus largement à l’usage des plateformes sociales dans le cadre des stratégie marketing qu’il s’agisse de maintenir des communautés de marques, d’amplifier la communication, d’acquérir de nouveaux clients. Sa perspective est celui d’une économie politique de plateformes.
Présentations utilisées en cours
- les médias sociaux et leur business model
- des communautés de marques au community management.
- Plateformes, gouvernementalité et gournance des algorithmes
Cette année une thématique centrale organise l’enseignement : “Les algorithmes des plateformes sociales”
Évaluation :
Deux éléments contribuent à l’évaluation :
a) Devoir sur table individuel
b) Une étude sous la forme d’un article de 8000 signes portant sur l’utilisation d’algorithme par un réseaux social.
Il s’agira dans chacun des cas d’analyser, sous une forme journalistique, dans quel but ces plateformes sociales emploient certains ensembles d’algorithmes, quels en sont les principes et les effets secondaires.
Quelques lectures
- Balagué, Christine, and David Fayon. Facebook, Twitter Et Les Autres-: Intégrer Les Réseaux Sociaux Dans Une Stratégie D’entreprise. Paris: Pearson, 2010,16.
- Benavent, C : “plateformes - Sites collaboratifs, Marketplaces, Réseaux sociaux : comment ils influencent nos choix” Fyp, 2016.
- Benavent, C : ” Big Data, Algorithme et marketing : rendre compte“. WP, Benavent.fr
- Eranti, The social significance of the Facebook Like button First Monday
- Kozinets, Robert V. “Social Brand Engagement: A New Idea.” GfK Marketing Intelligence Review 6.2 (2014).
- Muniz, Albert M., and Thomas C. O’guinn. “Brand Community.” J Consum Res Journal of Consumer Research 27.4 (2001): 412-32. Print.
- Etude sur les usages des réseaux sociaux dans le Monde UM Wave
- Enquête sur les community managers 2015
#WebblendMix bigdata : des études à l’action
 Le #Web blend Mix 2015 est enthousiaste, Lyonnais et cool. Ravi d’y avoir été invité.
Le #Web blend Mix 2015 est enthousiaste, Lyonnais et cool. Ravi d’y avoir été invité.
Quand au message à transmettre pendant la conf, c’est celui que je répète. Les données ne sont pas destinées principalement aux études, on en a déjà bien assez, et les données sans théorie sont comme l’eau sans conduite : elle se disperse et ne font rien pousser.
Les données sont là pour agir, agir en masse et de manière précise, elle fournissent le renseignement nécessaire pour activer une appli, préparer un vendeurs, motiver un acheteur. Elles ne sont rien sans les algorithmes, et les algorithme ne sont rien sans la compréhension des situations d’usage. Le big data en marketing crée de la valeur s’il est associé à un effort intelligent de modélisation, et si cette modélisation prend en compte le contexte social : le caractère performatif et politique des dispositions.
On concluera in fine, que l’usage intensif risque de s’accompagner d’une exigence sociale : celle de rendre compte des effets de cet emploi des données et des algorithme.