Les voyages sont faits pour être vécus mais ce qui en reste ce sont des mots. Des livres de voyageurs, le journal de bord des marins, et aujourd’hui le commentaire des expériences de consommation. A l’heure du post-exotisme ( pas celui-ci), quand le touriste pense rencontrer une culture authentique mais bien souvent façonnée par son propre regard, ce qui compte est moins ce que l’on a vécu que ce que l’on en garde : des selfies et le commentaire des lieux de séjours. C’est certainement moins poétique que Cooket Gauguin, mais plus profitable pour l’industrie du tourisme.
Et c’est à l’occasion d’un de ces voyages, avec l’aide des collègues du Cetop, des étudiants du master de marketing de l’UPF, et l’écoute du team de Tahiti tourisme, que nous nous sommes lancés dans l’analyse des sentiments exprimés par les touristes à propos de leur séjour avec une petite incursion dans les packages de text mining de r. Il n’y avait pas de meilleure place pour apprécier la critiques des auberges du paradis.
Pour la méthode, il s’agit d’abord de scrapper, avec les ressources du package rvest, le site de TripAdvisor. La Polynésie est isolée, trouvant ses clients dans trois grands bassins à plus de 10h de vol : l’Asie , les EU et la France. Il y a environ 150 hôtels et 300 pensions. Les résultats donnés dans cette note, sont établis sur la base d’une première extraction centrée sur Tahiti et portant sur 7700 commentaires. On généralisera plus tard sur les 77000 commentaires sur l’ensemble des archipels.
Ce corpus fait l’objet de deux types d’analyses comme on commence à le faire systématiquement dans ce type d’exercice : mesurer la tonalité positive ou négative (le sentiment) et les sujets évoqués ( topic analysis). Pour la première, on emploie tidytext, pour la seconde le modèle LDA du package Topicmodels.
Voici la présentation de travail (demo), avec quelques éléments de code, rendez-vous au piurn 2018 pour une présentation plus complète.
L’objectif de l’atelier, organisé dans le cadre des enseignement de l’ED EOS, est la prise en main de r au travers de l’interface graphique Rcmdr de Rstudio et du markdown.
Il s’agit aussi de découvrir la communauté r et ses ressources en 4 séances de 3 heures : décrire, expliquer, modéliser.
Public visé et pré requis : Doctorants et autres chercheurs. Connaissance des tests statistiques et autres statistiques élémentaires. Une habitude de SAS ou SPSS fera du bien.
Les participants doivent installer Rstudio au préalable. l’interface pour démarrer est Rcmdr, c’est le premier package à installer au préalable.
Calendrier de la formation (période de l’année): 19 et 20 décembre 2018 et 21 janvier 2019 (9h30-12h30 : 13h30-16h30) - Lieu : Université Paris Nanterre Bat A 3ème étage salle 304 ou 305)
Inscription : envoyer un CV à [email protected] avant le 10 décembre. - nombre maxi d’inscrits : 15.
Programme
Le jeu de donnée utilisé provient de l’European Social Survey. On s’intéressera en particulier à l’évolution de la confiance en France de 2002 à 2016 : on trouvera ici les données et le fichier markdown. Les résultats peuvent être consultable sur cette page. On regardera en complément ce document ( Bonheur et valeur dans 18 pays européens)
1 : l’environnement r: communauté, packages, langage et prise en main avec Rcmdr. Comparaison de moyennes, corrélation, représentation graphique avec ggplot(pour des exemples voir ici ou là )
2 : Clustering ( package Ape, dendro…) et analyses multidimensionnelles ( AF, AFC, MDS)
3 : Régression avec r: des MCOs au modèle linéaire généralisé (Logit, Poisson, etc) (package lme4, Stargazer pour des présentations standardisées.
4 : Échelles de mesure et équations structurelles avec Psych et Lavaan : on traitera notamment de l’influence de la confiance sur le bien être.
Une session supplémentaire le 21 janvier sera consacrée au text mining
5 : Analyse lexicale avec tm , Rtsne et LDA , vec2word, sentiment analysis et quanteda. Le cas de l’analyse de topics d’un flux de tweets. On s’appuiera sur le blog tex2r.
ECTS : la participation au séminaire donne droit à 3 crédits.
Ressources :
r blogger : un meta blog centré sur r , très riche en exemple et application.
StackOverflow : plateforme de Q&A pour les développeurs, r y est fréquemment mis en question
PS : un cours similaire est donné dans le cadre du Master Management de l’innovation GDO/MOPP.
La doc de ggplot2, le package des graphiques élégants.
Crédit Photo : comme souvent l’excellent Jeff Safi
Ces dernières années les progrès du text mining renouvellent largement l’étude des contenus textuels.
Un saut a été franchi depuis les techniques classiques d’analyse factorielles des correspondances. Les outils récents inspirés du ML peuvent remplacer ou au moins compléter les bonnes vieilles techniques de l’analyse lexicale.
Alors plutôt que de faire des Sudoku pendant les vacances, autant se balader dans les packages de r et d’appliquer ces techniques à un cas pratique. Pourquoi ne pas explorer justement ce que l’on dit de ces techniques sur les réseaux sociaux. Que dit-on de l’intelligence artificielle et du machine learning ? Quels en sont les sujets de conversation?
Commençons par le début. Il nous faut un corpus. Autant le prendre là où il est facile à capturer, c’est à dire dans Twitter.
La première étape consiste à créer un compte sur l’API (REST), pour pouvoir extraire ce que l’on souhaite ( avec des limites imposées par twitter). Et lLa seconde étape consiste simplement à se connecter à l’API, via r, et à lancer une requête. Ce qui se fait de manière simple avec le code suivant :
#accès à l api de twitter
consumerKey<-"Xq..."
consumerSecret<-"30l..."
access_token<-"27A..."
access_secret<-"zA7..."
setup_twitter_oauth(consumerKey, consumerSecret, access_token,access_secret)
Pour rechercher les tweets, on échantillonne sur plusieurs variantes de hashtag, en préférant la méthode des twits les plus récents (une alternative proposée par Twitter est de choisir les plus populaires, une troisième méthode mixant les deux approches). Il suffit ensuite de fusionner les fichiers, puis de dédupliquer les enregistrements identiques.
#recherche des twits avec plusieur requetes
tweets1 <- searchTwitter("#IA", n = 2000, lang = "fr", resultType = "recent", since = "2017-08-01")
tweets2 <- searchTwitter("#ML", n = 2000, lang = "fr", resultType = "mixed", since = "2017-08-01")
tweets3 <- searchTwitter("#AI", n = 2000, lang = "fr", resultType = "recent", since = "2017-08-01")
tweets4 <- searchTwitter("#MachineLearning", n = 2000, lang = "fr", resultType = "recent", since = "2017-08-01")
tweets5 <- searchTwitter("#Deeplearning", n = 2000, lang = "fr", resultType = "recent", since = "2017-08-01")
#transformer en data frame
tweets_df1 <- twListToDF(tweets1)
tweets_df2 <- twListToDF(tweets2)
tweets_df3 <- twListToDF(tweets3)
tweets_df4 <- twListToDF(tweets4)
tweets_df5 <- twListToDF(tweets5)
tweets_df <- rbind(tweets_df1,tweets_df2,tweets_df3,tweets_df4,tweets_df5)
Le décompte se faisant tout les quarts d’heure, on peut répéter l’opération pour récupérer quelques dizaines de milliers de tweets en quelques heures. Et si l’on a un peu de budget on changera d’Api pour streamer en temps réel ce que l’on souhaite.
On dispose donc d’un corpus d’environ 6000 tweets, dont il va falloir nettoyer le contenu. C’est l’opération la plus difficile, elle demande de l’astuce et une bonne compréhension des contenus. Dans notre cas, différentes opérations vont être menées et elles constituent l’étape essentielle où l’astuce de l’analyste est la clé de l’analyse.
Il faut aussi éliminer les liens URL, mais aussi les mentions
De même les nombres, la ponctuation, mettre en minuscule
Certains termes risque de n’apporter aucune information, les mots de liaisons, les articles, et naturellement les termes qui ont permis la sélection ( #IA par exemple)
et enfin réduire les termes à leurs racines pour éviter une trop grande fréquences de termes équivalents mais distincts ( poisson, poissonier) c’est l’opération de stemming qui identifie la racine du lexique constitué.
#recherche des twits avec plusieur requetes
# creation du corpus et nettoyage du texte
tweets_corpus <- Corpus(VectorSource(tweets_text))
removeURL <- function(x) gsub("http[[:alnum:][:punct:]]*", "", x) #enlever les liens
tweets_corpus <- tm_map(tweets_corpus, content_transformer(removeURL)) #enlever les liens
removeACC <- function(x) gsub("@\\w+", "", tweets_corpus) #enlever les comptes
tweets_corpus <- tm_map(tweets_corpus, content_transformer(removeACC)) #enlever les comptes
tweets_corpus <- tm_map(tweets_corpus, removeNumbers) #enlever les nombre
tweets_corpus <- tm_map(tweets_corpus, removePunctuation) # ici cela va supprimer automatiquement tous les caractères de ponctuation
tweets_corpus <- tm_map(tweets_corpus, content_transformer(tolower)) #mettre en minuscule
tweets_corpus <- tm_map(tweets_corpus, removeWords, stopwords("french")) #supprimer automatiquement une bonne partie des mots français "basiques"
tweets_corpus <- tm_map(tweets_corpus, stripWhitespace) # ici cela va supprimer automatiquement tous les espaces vides
tweets_corpus <- tm_map(tweets_corpus, stemDocument, language = "french") #on cherche les radicaux des termes
tweets_corpus <- tm_map(tweets_corpus, removeWords,c("ai", "machinelearning","ia","ml", "deeplearning","rt")) #enlever le terme commun
tdm <- TermDocumentMatrix(tweets_corpus, control=list(wordLengths=c(5, 30))) #creation de la matrice termsXdocuments
On conduit cette opération avec les ressources du packagetm qui est le véritable moteur du text mining. C’est une opération très empirique, la procédure se construit de manière itérative, en prenant soin de bien séquencer les différentes actions. Et il sera particulièrement utile de regarder ce que font les autres data-scientists, leurs astuces et les élégances de langage qu’ils emploient. C’est l’étape la plus difficile, d’un point de vue technique mais aussi pragmatique.
La première commande transforme le fichier de données dans un format particulier qui est celui qui décrit le corpus. Chaque enregistrement est codé sous la forme d’un triplet : le terme ( un mot racine), le document ( un tweet) et la fréquence d’apparition du terme dans le document. Pour l’utilisateur d’un logiciel statistique classique, SPSS, c’est l’élément le plus troublant, r ne fonctionne pas simplement avec des tableaux individusXvariables, ses objets sont beaucoup plus subtils, complexes mais pratiques. Les commandes précedentes effectuent les transformations requises du corpus. La dernière crée la matrice termes document que nous voulons étudier.
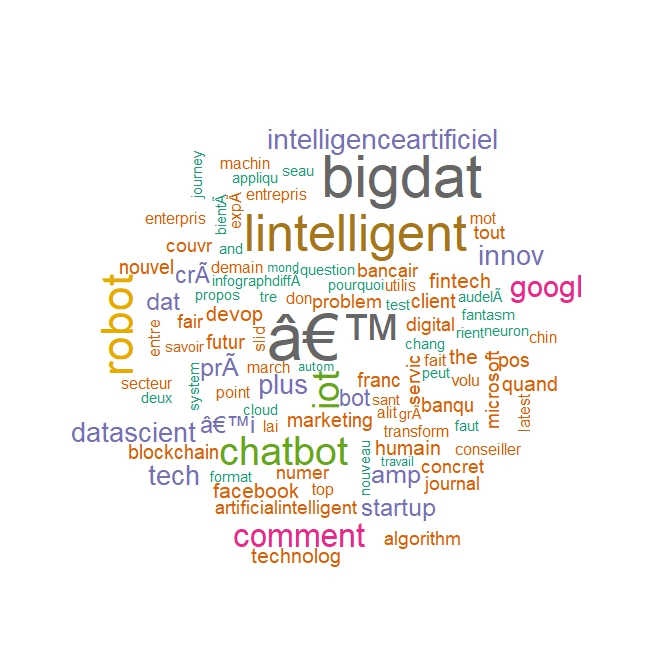
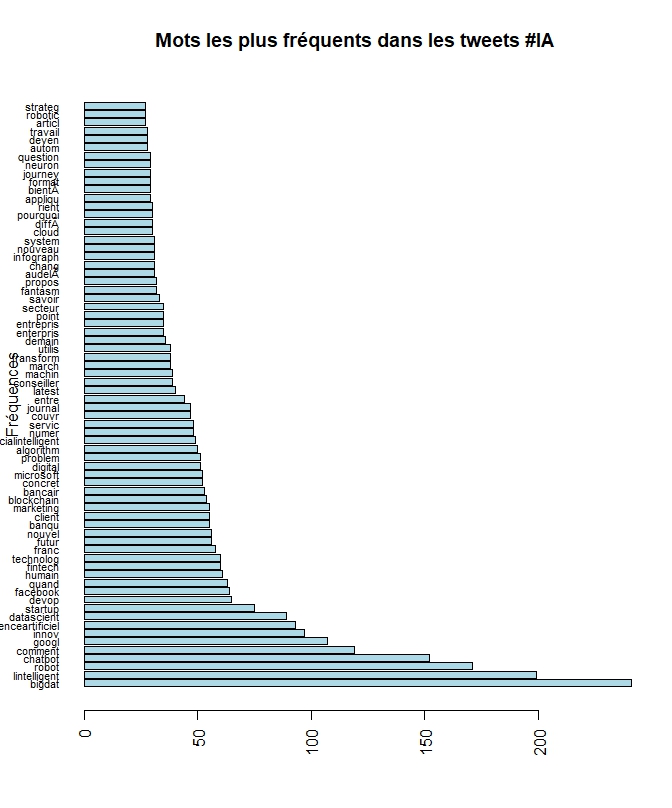
Comme à l’ordinaire, débutons par le plus simple : quels sont les termes les plus fréquents? A cette fin, deux technique peuvent être employées. La première est simplement la représentation ordonnée par la fréquence des termes, la seconde, très visuelle est de produire une représentation très populaire, celle des nuages de mots. En fonction de ces résultats on pourra réitérer les opérations précédentes et ajuster le jeu de données et sélectionner les termes que l’on veut analyser. En voici le code et les résultats.
cloudword
FréquenceMot
dim(tdm)
nTerms(tdm)
m <- as.matrix(tdm)
v <- sort(rowSums(m), decreasing = TRUE)
d <- data.frame(word = names(v),freq = v)
head(d, 350)
barplot(d[1:70,]$freq, las = 2, names.arg = d[1:70,]$word,
col ="lightblue", main ="Mots les plus fréquents dans les tweets #IA",
ylab = "Fréquences", horiz=TRUE, cex.names = .7)
x11() #pour ne pas ecraser le chart precedent
set.seed(123456)
wordcloud(tweets_corpus, max.words = 100, colors = brewer.pal(8, "Dark2"))
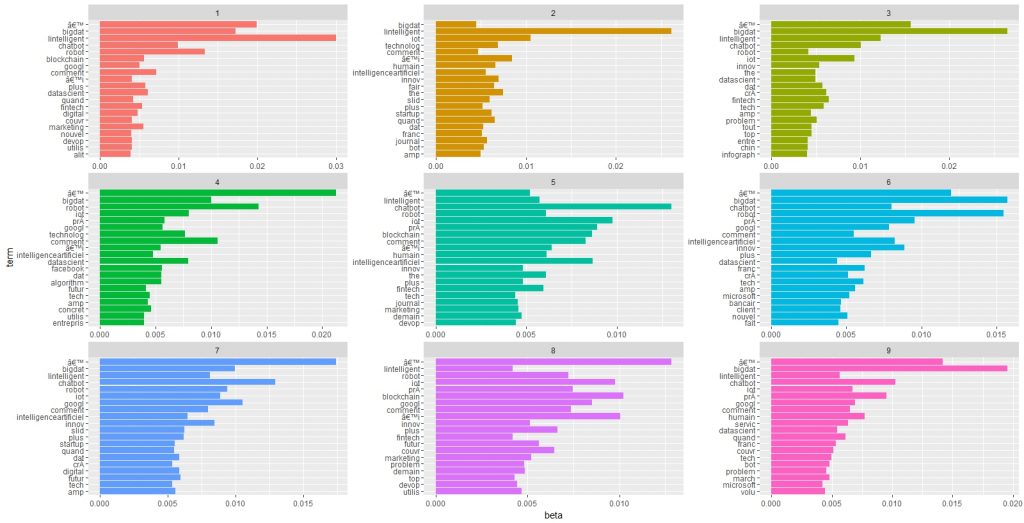
Les choses sérieuses viennent maintenant avec l’utilisation d’une méthode de modélisation des topics. On emploie ici le package ModelTopics et la méthode LDA ( Latent Dirichlet Allocation) , qui cherche à calculer la probabilités qu’un terme appartienne à un Topic, et qu’un topic appartiennent à un document, en ne connaissant que l’appartenance des termes aux document. L’idée est de prendre en compte que chaque document est un mélange de topic, et que chaque topic est un mélange de mots. On en trouvera une excellente présentation ici dont nous avons repris des éléments de code, pour une présentation plus technique la page Wikipedia est un bon début.
Le résultat principal est constitué par le diagramme suivant qui représente pour chaque topic ( on a choisit d’en identifier 9 de manière avouons le arbitraire - la question de la détermination du nombre optimum n’est pas encore résolue). Les valeurs sont les probabilités ( beta) que les termes soient associés aux topics. C’est une sorte de spectre lexical. Le topic 5, par exemple semble être relatifs aux chatbots, à l’IoT et à ses applications en marketing et dans les fintech.
Avouons- le l’interprétation n’est pas évidente. Nous avons besoin d’un nettoyage plus poussé et sans doute de jouer encore plus sur les paramètres du modèle qui consistent d’abord dans le nombre de sujets (topics) qui mérite sans doute d’être plus élevés, et dans un paramètre Alpha qui ajuste le nombre de mots associés aux sujets. Encore mieux, il serait bon d’implémenter le package Ldavis qui produit une visualisation remarquable.
On pourrait aller encore plus loin en considérant ce premier modèle comme un modèle d’entrainement, puis en l’utilisant pour classifier de nouveaux documents. Ainsi, imaginons d’extraire chaque jour un nouveau jeu de données, on peut imaginer construire un outils qui donne l’évolution des thématiques dans la conversation des réseaux-sociaux. Il nous suffira de la commande suivante :
test.topics <- posterior(train.lda,test)
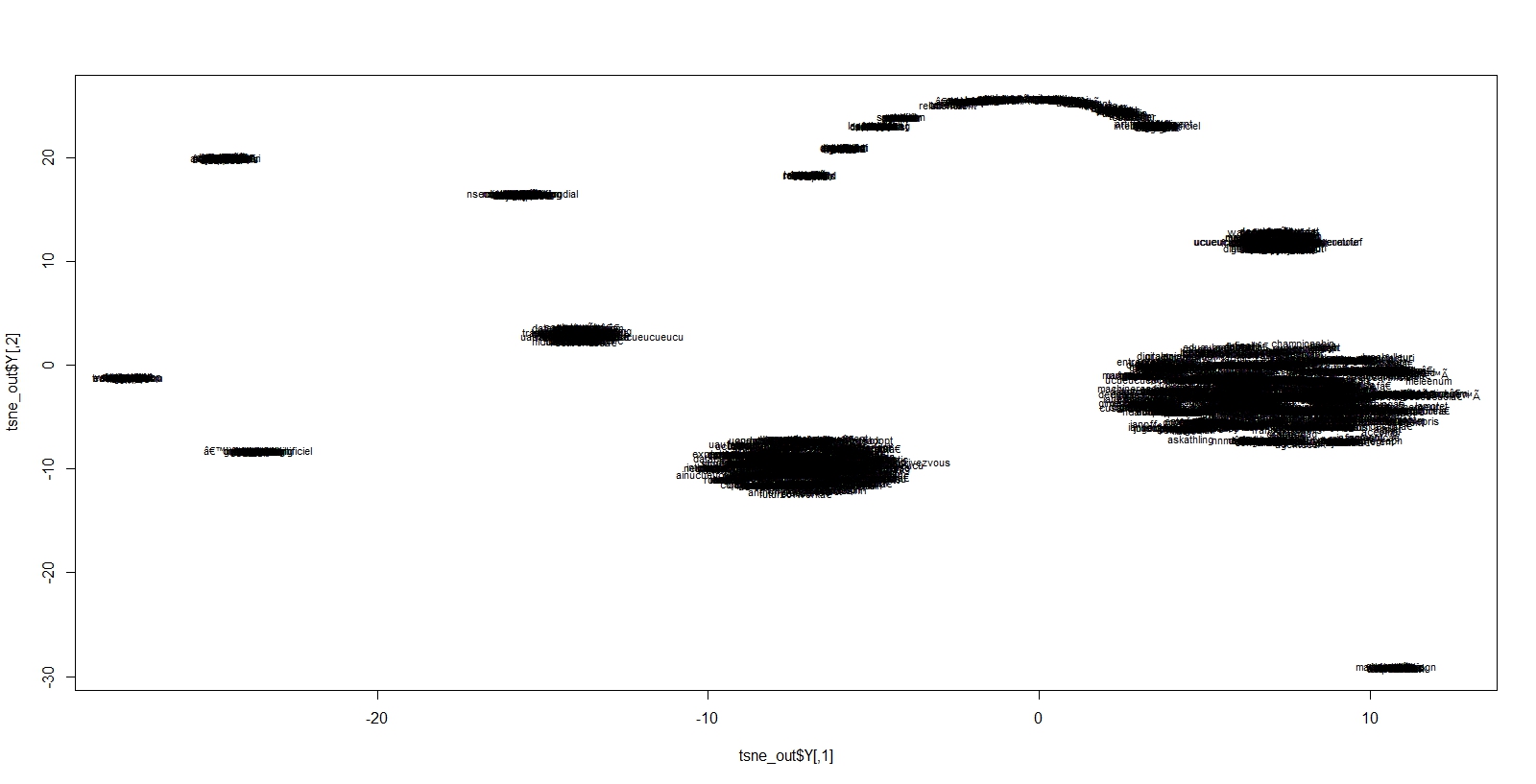
Une autre approche est celle de la méthode Tsne, fournit par le package Rtsne. C’est finalement une sorte d’analyse des similarités, à la manière du MDS ( Multi Dimensionnal Scaling) mais qui mets en jeu des calculs de distances très particulier, dont la vertu principal est de rendre compte de niveaux d’échelles différents. Ce qui est très proche sera plus ou moins éloignés, ce qui est loin est plus ou moins rapprochés. On échappe au phénomène de dégénérescence du vieux MDS, et à une meilleure représentation quand les objets sont éloignés. On contrôle ceci par un paramètre de perplexité, qui reflète sommes toute le nombre de voisins pris en compte dans les calculs. On lira ceci pour mieux en comprendre les effets.
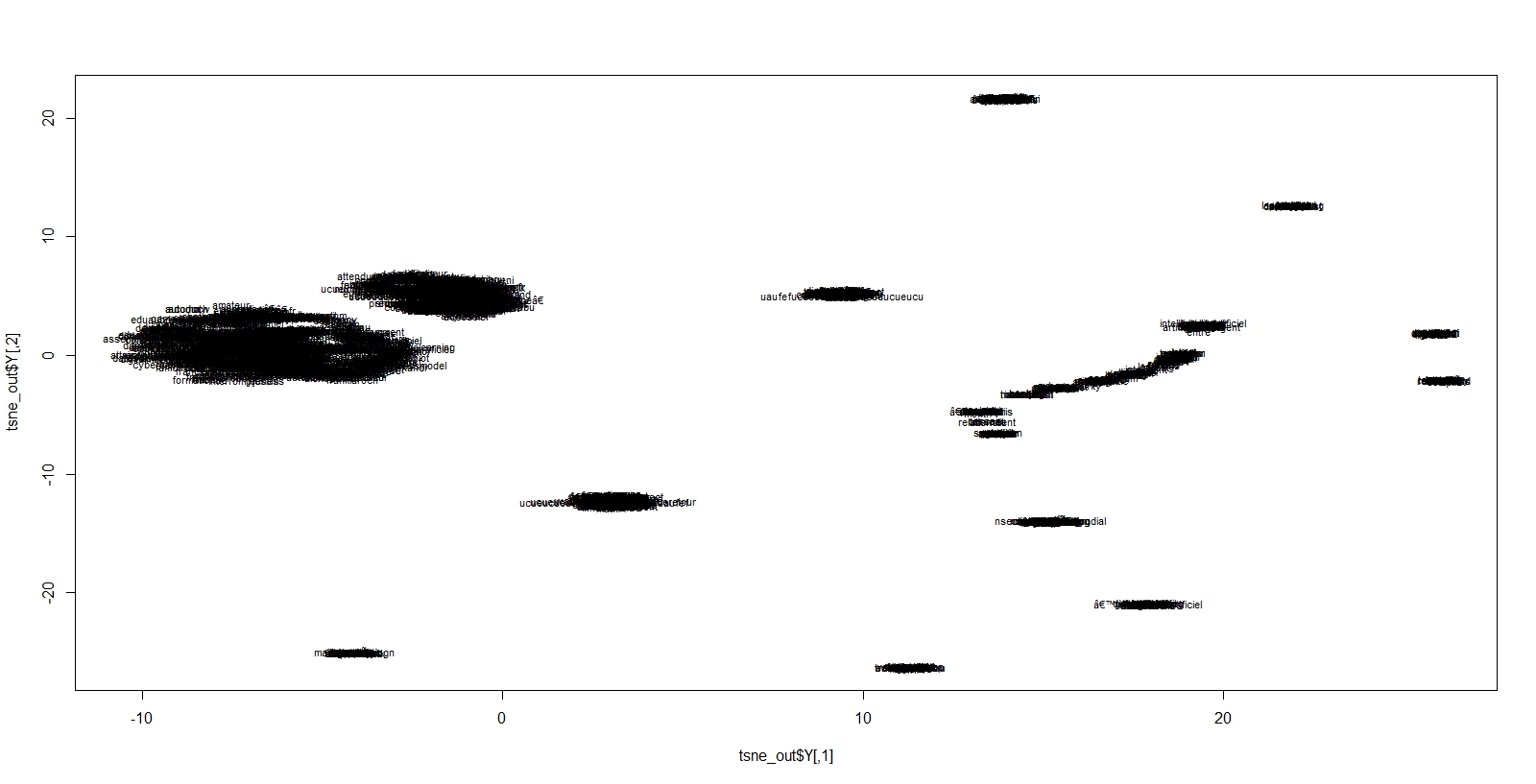
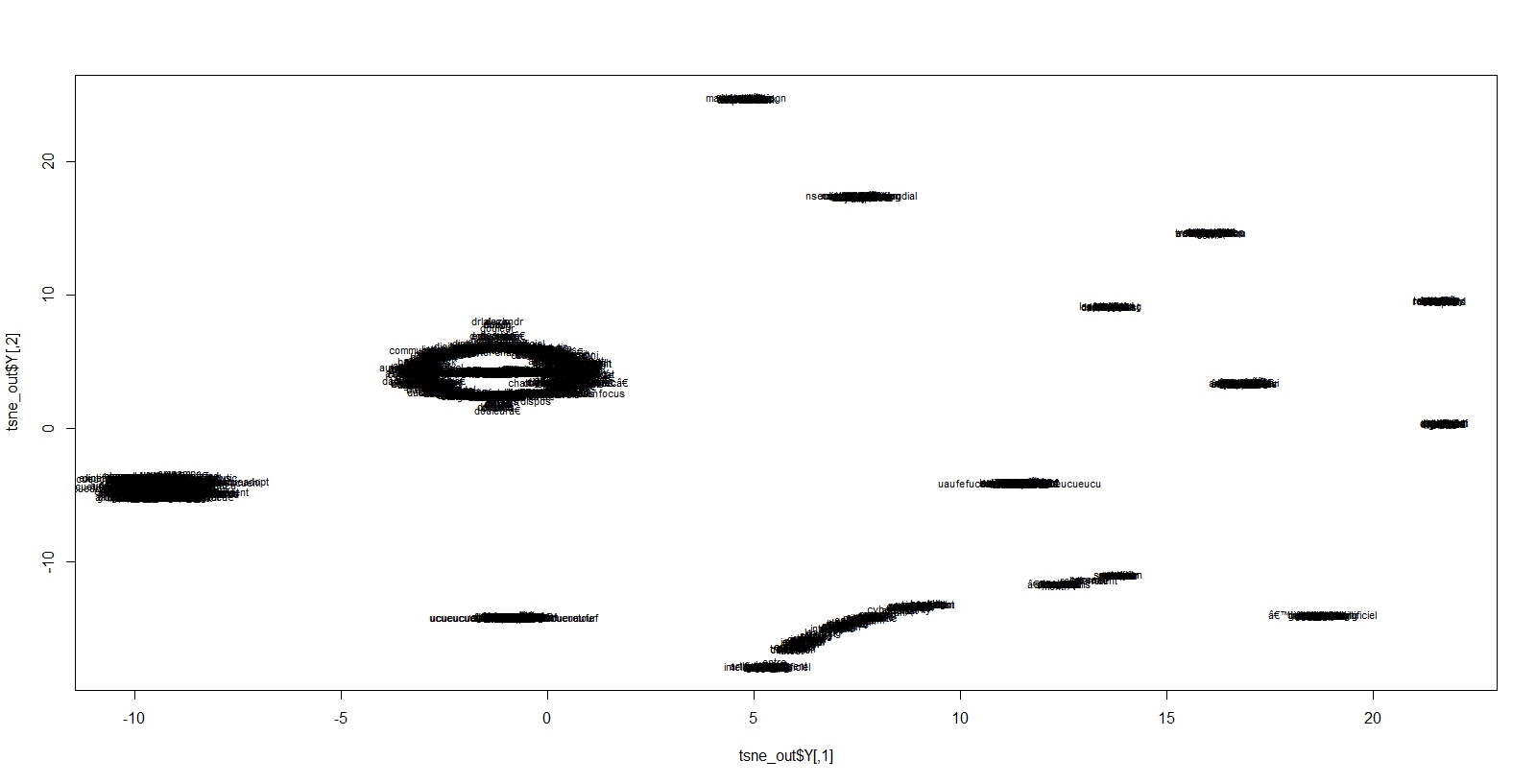
En voici les résultats pour plusieurs degrés de perplexité. La représentation est illisible ( il y a environ 4000 termes) mais des groupes de mots bien distincts apparaissent. Elle va nous servir de base pour une meilleure visualisation de cet espace.
perplex30
perplex15
perplex5
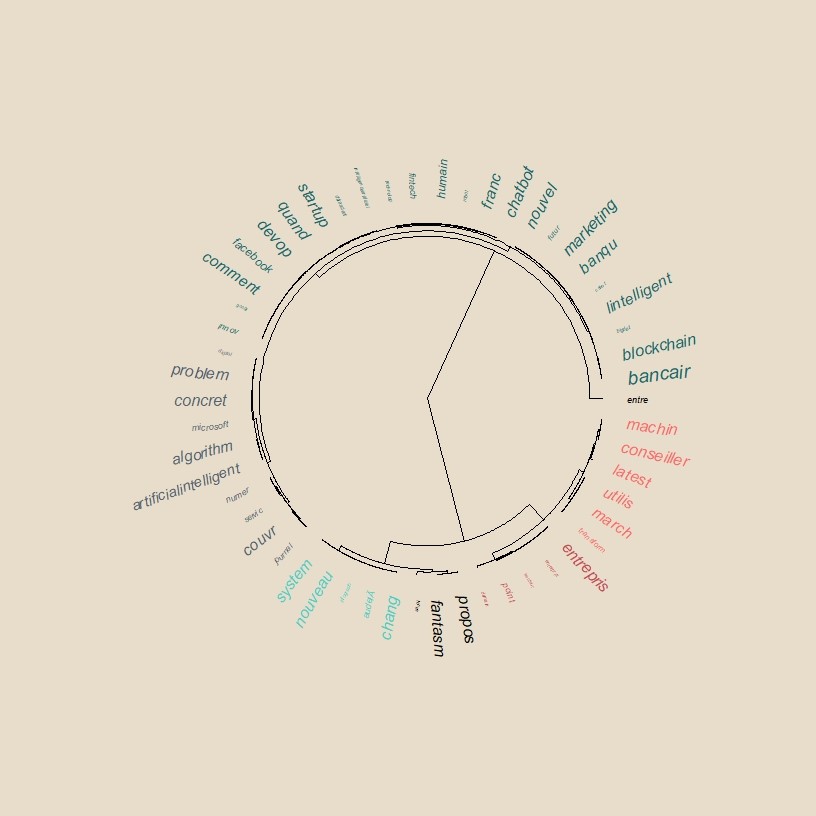
Un modèle avec une perplexité de 20 et à 2 dimensions est choisi comme base d’une meilleure visualisation. On va se concentrer sur les termes les plus fréquents et l’on applique une méthode de classification (méthode de ward) dans l’espace définit par tsne, et avec un peu de code supplémentaire, on produit un dendogramme radial produit par le package Ape, dans lequel la taille relative des termes est proportionnelle à leur fréquence et les couleurs correspondent à un découpage en 7 classes.
X1<-tsne_out$Y[,1]
X2<-tsne_out$Y[,2]
Fq<-rowSums (tdmdata, na.rm = FALSE, dims = 1)
Rtsne<-data.frame(Fq,X1, X2)
Rtsne2 <- subset(Rtsne, subset=Fq>30, select=c(X1,X2))
#clustering
m2 <- as.matrix(Rtsne2)
distMatrix <- dist(scale(m2))
fit <- hclust(distMatrix, method = "ward.D2")
p<-plot(fit)
rect.hclust(fit, k = 7) # cut tree into 7 clusters
library(ape)
plot(as.phylo(fit), type = "unrooted")
plot(as.phylo(fit), type = "fan")
# vector of colors
mypal = c("#556270", "#4ECDC4", "#1B676B", "#FF6B6B", "#C44D58")
# cutting dendrogram in 7 clusters
clus = cutree(fit, 7)
# plot
op = par(bg = "#E8DDCB")
# Size reflects frequency
plot(as.phylo(fit), type = "fan", tip.color = mypal[clus], label.offset = 1, cex = log(Rtsne$Fq, 10), col = "red")
Voici le trail! On y lit plus clairement les sujet : on peut commençant en descendant à droite par un premier thème sur les chatbots et de Facebook naturellement qui se poursuit sur une thématique marketing et bancaire, les applications. Le troisième thème, en rouge est plus centré sur l’entreprise et l’organisation, l’impact sur les conseillers. Les thèmes du fantasme et du changement nécessaire s’enchaîne assez logiquement, un sixième thème se centre sur la résolution de problème, le dernier est relatif aux questions entrepreuneuriales et aux start-up.
On aura condensé ainsi un contenu brut de 7000 tweets et 4000 mots en une image.